Cohere Command A+
Cohere Command A+ is a 218B sparse MoE model with Apache 2.0 license, native citations, and a 128K context window that runs on just two H100 GPUs.

Command A+ is Cohere's largest and most capable model to date, and the first in the Command family built on a sparse Mixture-of-Experts architecture. Released May 20, 2026 under a full Apache 2.0 license, it's the only frontier-class enterprise model from a major Western lab that developers can download, quantize, and run on-premises without restrictions on commercial use or revenue caps.
TL;DR
- Best at enterprise RAG and agentic workflows with native citation grounding built into the architecture
- 218B total parameters, 25B active per token, 128K context, $2.50/M input tokens
- Scores 37 on the Artificial Analysis Intelligence Index - well below GPT-5.5 (60) or Claude Opus 4.7 (57), but the only fully open model in this deployment class
The model identifier is command-a-plus-05-2026. At 218B parameters with 25B active per token, it targets the same compute efficiency point as DeepSeek V3 and Qwen's MoE variants - but with an enterprise feature set that neither of those models matches out of the box. Cohere also ships W4A4 and FP8 quantized weights with the full BF16 version, all under the same license.
One feature that sets Command A+ apart: native citation generation. When the model pulls information from a retrieval context, it emits structured <|START_THINKING|> plan blocks and <|START_ACTION|> tool-call blocks, and it explicitly links factual claims to source spans via grounding tags. This isn't a post-processing layer - it's baked into the generation process, which means the citation quality and latency characteristics are different from typical RAG pipelines. For enterprise deployments where audit trails matter (legal, compliance, healthcare), that's a meaningful distinction.
Key Specifications
| Specification | Details |
|---|---|
| Provider | Cohere |
| Model Family | Command |
| Parameters | 218B total / 25B active per token |
| Architecture | Sparse MoE (128 experts, 8+1 active) |
| Context Window | 128K tokens input / 64K tokens output |
| Modalities | Text, image (input); text (output) |
| Input Price | $2.50/M tokens |
| Output Price | $10.00/M tokens |
| Release Date | 2026-05-20 |
| Knowledge Cutoff | April 1, 2025 |
| Languages | 48 |
| License | Apache 2.0 |
Benchmark Performance
The honest summary: Command A+ isn't a frontier reasoning model. Its Intelligence Index score of 37 places it below models like Mistral Medium 3.5 (39) and well below the closed-source leaders. Where it actually punches hard is on agentic benchmarks, which better reflect its intended use case.
| Benchmark | Command A+ | Mistral Medium 3.5 | GPT-5.5 |
|---|---|---|---|
| Artificial Analysis Intel Index | 37 | 39 | 60 |
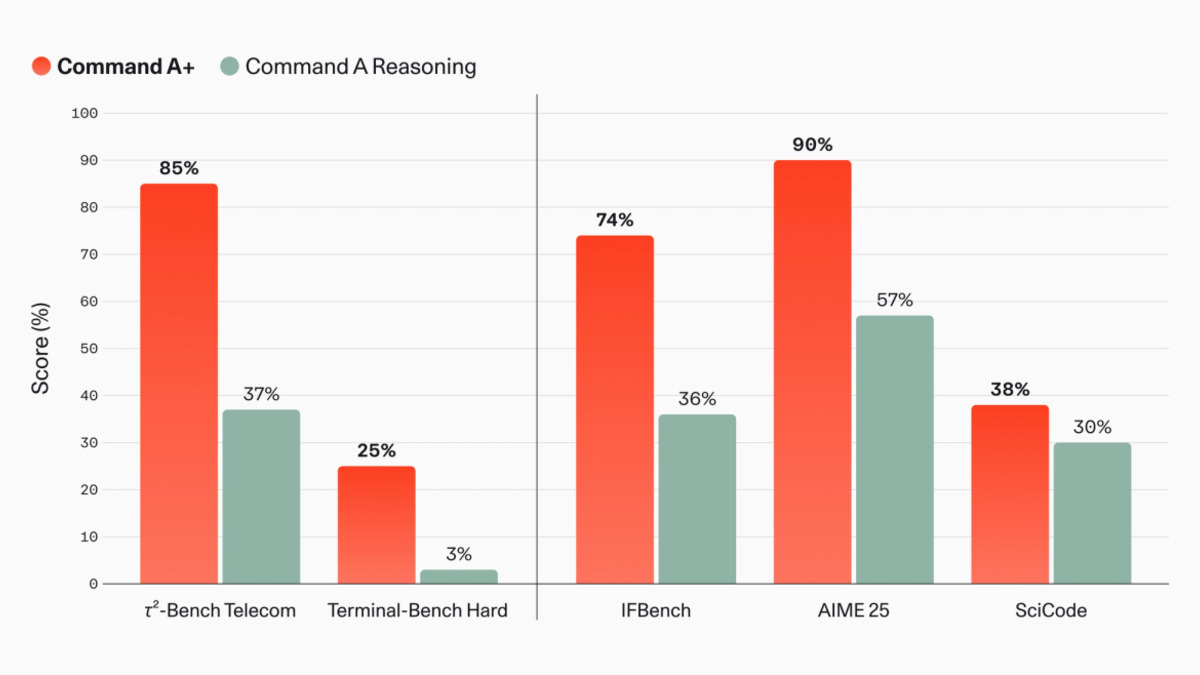
| τ²-Bench Telecom (agentic) | 85% | Not published | Not published |
| GPQA Diamond | 76% | ~60% | Not published |
| AIME 2025 | 90% | Not published | Not published |
| MMMU | 75.1% | Not published | Not published |
| MathVista | 80.6% | Not published | Not published |
The τ²-Bench Telecom score is the headline: 85%, up from 37% on the previous Command A Reasoning model. That's not a small improvement - the prior model was effectively unusable on multi-step tool use tasks. Terminal-Bench Hard (agentic coding) moved from 3% to 25%. These are the benchmarks Cohere built the model against, so take the magnitude with some skepticism, but the direction of improvement is real.
GPQA Diamond at 76% and AIME 2025 at 90% are more surprising - they're competitive with models that score higher on general intelligence composites. The model appears to have disproportionate strength on structured reasoning tasks relative to its overall index score.
The weak spot is Humanity's Last Exam (HLE) at around 11%, which tests broad scientific knowledge across obscure domains. Command A+ isn't designed for that task class.
 Benchmark data from Cohere's official Command A+ announcement, May 2026.
Source: cohere.com
Benchmark data from Cohere's official Command A+ announcement, May 2026.
Source: cohere.com
Key Capabilities
Native Citations and Enterprise RAG
The native citation system is the feature most enterprise teams will care about. When Command A+ generates an answer from retrieved documents, it doesn't just synthesize the result - it produces explicit grounding spans that link each claim to a specific source. The architecture uses special tags embedded in generation, so the citation data is structurally part of the output rather than scraped from it after the fact. For teams building RAG systems where every factual claim needs to trace back to a document, this removes a layer of post-processing complexity.
Internal evaluations from Cohere show 20% accuracy improvement on agentic QA tasks and 32% quality improvement on spreadsheet analysis over the previous Command A Reasoning model. These are LLM-as-judge scores with obvious methodological caveats, but the directional gains are consistent with the benchmark data.
Deployment Efficiency
The quantization story is the other major selling point. Command A+ ships with lossless W4A4 weights produced through Quantization-Aware Distillation - a process that quantizes only the MoE expert layers to 4-bit while keeping attention pathways at full precision. The result runs on 2×H100 80GB GPUs or a single NVIDIA B200, at roughly 375 output tokens per second with 113ms time-to-first-token. For comparison, the BF16 version requires 8×H100s.
That 4× reduction in GPU footprint is why "sovereign AI" appears prominently in Cohere's positioning. An organization that needs an enterprise-grade model but can't or won't route data through a US cloud provider can deploy Command A+ on its own infrastructure at a realistic hardware cost.
 Hardware requirements and quantization formats for Command A+ deployment.
Source: cohere.com
Hardware requirements and quantization formats for Command A+ deployment.
Source: cohere.com
Multilingual Coverage
Command A+ expands Cohere's language support from 23 to 48 languages, including all official EU languages. The tokenization efficiency improvements are standout for non-Latin scripts: Arabic gained 20% efficiency, Korean 16%, Japanese 18%. This matters for enterprise customers in non-English markets where tokenizer overhead has historically penalized inference costs on Asian and Middle Eastern languages.
Pricing and Availability
At $2.50/M input tokens and $10.00/M output tokens via the Cohere API, Command A+ is priced comparably to Mistral Medium 3.5 ($1.50/$7.50) and well below Claude Opus 4.7 ($25.00/$125.00). The pricing matches the previous Command A model, so this is a straight upgrade for existing Cohere API users with no cost increase.
The weights are available on Hugging Face under CohereLabs/command-a-plus-05-2026 in all three formats (BF16, FP8, W4A4). Apache 2.0 licensing means no usage caps, no revenue thresholds, and no non-compete clauses - a legal posture that matters for enterprise procurement teams comparing it to models with modified licenses or commercial restrictions.
Cohere also offers managed inference through its Model Vault product and provides free trial access through its standard API key tier (rate-limited, not for production use).
Notably, Command A+ isn't yet available on major cloud platforms - no Amazon Bedrock, SageMaker, Azure AI Foundry, or Oracle OCI listings as of the release date. Teams wanting managed cloud deployment will need to use Cohere's own platform or self-host.
Strengths and Weaknesses
Strengths
- Architecture-level native citations make it the strongest option for RAG applications requiring audit trails
- Apache 2.0 license with no commercial restrictions, unlike many open-weight competitors
- Runs on 2×H100 GPUs at W4A4, enabling cost-effective private deployment
- 48-language support with improved tokenization efficiency for Arabic, Korean, and Japanese
- GPQA Diamond (76%) and AIME 2025 (90%) scores are competitive above its weight class
Weaknesses
- Intelligence Index of 37 lags significantly behind frontier closed models (GPT-5.5 at 60, Claude Opus 4.7 at 57)
- Knowledge cutoff of April 1, 2025 - over a year behind the release date
- HLE score of ~11% suggests weak performance on broad scientific reasoning tasks
- No availability on major cloud platforms at launch; Cohere's own API infrastructure only
- $10.00/M output pricing is higher than DeepSeek V4 ($1.10) for teams that can accept MIT licensing
Related Coverage
- Cohere Command A Vision - the previous flagship, a 112B multimodal model
- Cohere Acquires Aleph Alpha in $20B Sovereign AI Deal - context for Cohere's enterprise AI strategy
- Agentic AI Benchmarks Leaderboard - τ²-Bench rankings and methodology
- Cohere's Tiny Aya Fits 70 Languages Into 3.35 Billion Parameters - Cohere's multilingual research direction
FAQ
Is Command A+ truly Apache 2.0?
Yes. The weights, tokenizer, and configuration are all released under Apache 2.0 with no commercial restrictions, revenue caps, or non-compete clauses. This is different from models with modified licenses that restrict production use or enterprise revenue.
What does "native citations" mean in practice?
Command A+ generates explicit grounding spans during inference that link each factual claim to a specific source document. This is built into the generation process via special tokens, not added as a post-processing step. The result is a structured citation that includes exact source spans rather than just document-level attribution.
How does Command A+ compare to DeepSeek V4 for enterprise use?
DeepSeek V4 is cheaper ($0.27/M input vs $2.50) and likely faster via its own API, but it uses a MIT license with less clarity for enterprise procurement teams and lacks Command A+'s native citation system. Command A+ has a clear advantage for RAG and compliance-heavy deployments.
Can I run Command A+ on a single GPU?
Yes - the W4A4 quantized version runs on a single NVIDIA B200 GPU (192GB HBM3e). On H100 hardware you need two 80GB cards. The BF16 version requires 8×H100s.
What is the context window limit?
Command A+ accepts up to 128K input tokens and produces up to 64K output tokens per call.
Sources:
✓ Last verified June 2, 2026
