Claude Opus 4.7
Anthropic's latest flagship model ships with 3x higher resolution vision, a new xhigh effort level, task budgets for cost control, cyber safeguards, and 13% better coding performance at the same $5/$25 pricing.
Overview
Anthropic released Claude Opus 4.7 on April 16, 2026, positioning it as the successor to Opus 4.6 with a focus on reliability, vision, and autonomous task handling. The pitch: hand off harder work with less supervision.
TL;DR
- Strongest coding model available: +13% on GitHub AI's 93-task benchmark, 70% on CursorBench (vs 58% for Opus 4.6), 3x more resolved on Rakuten-SWE-Bench
- Vision accepts 3x more pixels (2,576px long edge, ~3.75MP) at the same price point ($5/$25 per M tokens)
- New xhigh effort level, task budgets (beta), and /ultrareview in Claude Code
The model ships at the same $5/$25 pricing as its predecessor, carries the cybersecurity safeguards Anthropic committed to building before releasing Mythos-class capabilities more broadly, and defaults to a new xhigh effort level in Claude Code that sits between high and max.
The real validation comes from third-party benchmarks. Cursor measured 70% vs 58% on their internal CursorBench. Rakuten found 3x more production tasks resolved. GitHub AI saw a 13% improvement across 93 coding tasks. These aren't Anthropic's own evals - they're from companies running the model against their own workloads.
Key Specifications
| Specification | Details |
|---|---|
| Provider | Anthropic |
| Model Family | Claude |
| Model ID | claude-opus-4-7 |
| Parameters | Not disclosed |
| Context Window | 1M tokens |
| Max Output | 128K tokens |
| Input Price | $5.00/M tokens |
| Output Price | $25.00/M tokens |
| Release Date | April 16, 2026 |
| License | Proprietary |
| Effort Levels | low, medium, high, xhigh (new), max |
| Vision Max Resolution | 2,576px long edge (~3.75MP) |
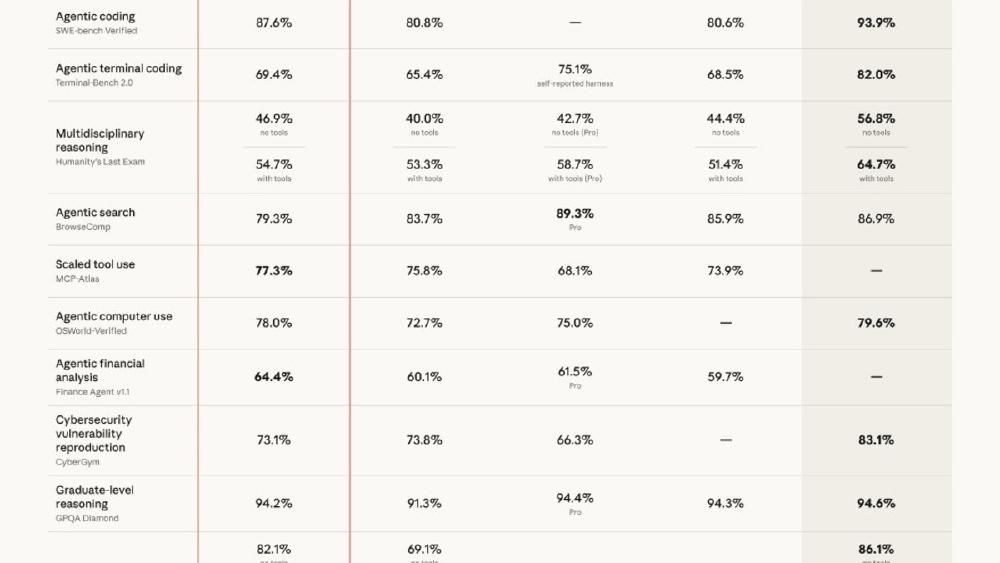
Benchmark Performance
| Benchmark | Opus 4.7 | Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| CursorBench | 70% | 58% | N/A | N/A |
| GitHub AI (93-task) | +13% | baseline | N/A | N/A |
| Rakuten-SWE-Bench | 3x tasks | baseline | N/A | N/A |
| Finance Agent (General) | 0.813 | 0.767 | N/A | N/A |
| BigLaw Bench (Harvey) | 90.9% | N/A | N/A | N/A |
| GPQA Diamond | TBD | 91.3% | 92.8% | 94.3% |
| SWE-Bench Verified | TBD | 80.8% | 77.2% | 80.6% |
| Chatbot Arena Elo | TBD | ~1504 | ~1484 | ~1500 |
GPQA Diamond, SWE-Bench Verified, and Arena Elo are not yet available for Opus 4.7. Anthropic's announcement focused on domain-specific third-party evaluations rather than standard academic benchmarks. We'll update this table as independent results come in.
The CursorBench result (+12 points over Opus 4.6) is the strongest signal. Cursor's benchmark measures real IDE coding workflows, not isolated function generation. A 12-point jump on a benchmark designed by a company that has no incentive to inflate Anthropic's numbers is meaningful.
Key Capabilities
Vision at 3x resolution
The jump from ~850px to 2,576px on the long edge means Opus 4.7 can process images at roughly 3.75 megapixels - more than three times previous Claude models. For document analysis, the model can now read standard-size text in full-page scans without preprocessing. For design work, it can evaluate UI mockups at near-production resolution. For charts and diagrams, fine labels and small data points are now legible.
xhigh effort and task budgets
The new xhigh effort level provides a middle ground between high (fast, cheaper) and max (thorough, expensive). It's now the default in Claude Code, meaning users get better reasoning out of the box without opting into the full cost of max.
Task budgets (beta on the API) let you set a token limit for a multi-step task. Claude manages allocation across steps rather than burning through the budget on the first call. This addresses the quota exhaustion problem that Max users have been documenting.
Cyber safeguards
Opus 4.7 includes automatic detection and blocking of high-risk cybersecurity requests. This is the production implementation of the safety measures Anthropic promised during the Project Glasswing announcement. Legitimate security professionals can apply to the Cyber Verification Program for exemptions covering vulnerability research, penetration testing, and red teaming.
/ultrareview in Claude Code
The new /ultrareview command runs a dedicated review session that reads through your session's changes and flags issues a careful human reviewer would catch. Three free ultrareviews per session for Pro and Max users.
Pricing and Availability
Same pricing as Opus 4.6:
| Tier | Input | Output |
|---|---|---|
| Standard (<=200K context) | $5.00/M tokens | $25.00/M tokens |
| Extended (>200K context) | $10.00/M tokens | $37.50/M tokens |
Available on: claude.ai, Claude Platform API, Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry.
Tokenizer change: Opus 4.7 uses an updated tokenizer that maps the same input to 1.0-1.35x more tokens depending on content type. Anthropic says the net effect is favorable for coding tasks despite the higher token count, but monitor your bills during the transition.
Strengths
- Third-party verified coding improvements (Cursor, Rakuten, GitHub AI)
- 3x vision resolution at no price increase
- Task budgets address the biggest user complaint (quota drain)
- xhigh effort gives a practical default between speed and thoroughness
- Cyber safeguards enable broader capability distribution
Weaknesses
- Standard benchmarks (GPQA, SWE-Bench, Arena Elo) not yet published
- Updated tokenizer may increase token counts 1.0-1.35x on existing prompts
- "More literal" instruction following may break prompts tuned for 4.6
- No parameter count disclosed (as usual for Anthropic)
Related Coverage
- Claude Opus 4.7 Launch - Full News Coverage
- Claude Opus 4.6 Model Card
- Claude Opus 4.6 Review
- Project Glasswing - $100M Cybersecurity Coalition
- Claude Mythos Preview - Cyber Capabilities
- Opus 4.7 Rumors and GPT-5.4-Cyber
- Overall LLM Rankings - April 2026
Sources:
✓ Last verified April 16, 2026
