Claude Opus 4.5
Anthropic's November 2025 flagship model delivers top SWE-bench scores, a new effort parameter for reasoning control, and a 66% price cut from its predecessor.

Claude Opus 4.5 is Anthropic's November 2025 flagship release, positioned above Sonnet 4.5 and below the later Opus 4.6/4.7 updates. At launch it held the highest SWE-bench Verified score of any publicly available model and introduced the effort parameter - a first-class API knob that lets developers dial reasoning depth from low to high without switching models. At $5/$25 per million tokens, it also cut the cost of Opus-class intelligence by 66% versus Opus 4.1's $15/$75 pricing.
TL;DR
- Top SWE-bench Verified score at launch: 80.9%, ahead of Gemini 3 Pro (76.2%) and GPT-5.1 (76.3%)
- 200K context window, 64K max output, $5/$25 per million tokens (66% cheaper than Opus 4.1)
- Extended thinking with a tunable
effortparameter; later superseded by Opus 4.6 and 4.7
Overview
Anthropic shipped Claude Opus 4.5 on November 24, 2025, as the next step in the Claude 4 family. The release focused on three things: software engineering capability, long-horizon agentic reliability, and cost efficiency. The SWE-bench Verified score of 80.9% was a meaningful gap over the competition at launch and the model's Terminal-Bench Hard score of 44% was the highest of any model tested at the time.
The effort parameter is probably the most developer-friendly addition. Instead of managing raw thinking_budget tokens, you set effort to low, medium, or high. At medium effort the model matches the performance of prior top-tier models while using 76% fewer reasoning tokens. At high effort it tops Sonnet 4.5 by around 4 points on coding tasks while cutting token use roughly in half compared to unconstrained extended thinking.
Context handling also improved. Opus 4.5 supports automatic context summarization for extended conversations, which prevents runaway token counts in multi-turn agentic workflows. The model caches prior thinking blocks by default in multi-turn sessions, so agents don't pay the full reasoning cost on every follow-up turn. Anthropic also tightened prompt injection resistance significantly - independent testing put the attack success rate at 4.7% versus 12.5% for Gemini 3 Pro and 21.9% for GPT-5.1.
By May 2026, Opus 4.5 is a legacy model. The Claude Opus 4.6 and Claude Opus 4.7 releases have overtaken it on every benchmark. It remains available via the API under the pinned ID claude-opus-4-5-20251101 and is still a reasonable choice if you have existing prompts tuned against its behavior and don't want to re-validate.
Key Specifications
| Specification | Details |
|---|---|
| Provider | Anthropic |
| Model Family | Claude 4 |
| Parameters | Not disclosed |
| Context Window | 200K tokens |
| Max Output | 64K tokens |
| Input Price | $5.00/M tokens |
| Output Price | $25.00/M tokens |
| Cache Write (5 min) | $6.25/M tokens |
| Cache Write (1 hr) | $10.00/M tokens |
| Cache Read | $0.50/M tokens |
| Batch API | 50% discount |
| Release Date | 2025-11-24 |
| API ID | claude-opus-4-5-20251101 |
| License | Commercial (Anthropic API TOS) |
| Knowledge Cutoff | May 2025 (reliable) / Aug 2025 (training) |
Benchmark Performance
Numbers below are from Anthropic's launch post, Vellum's independent analysis, and the Artificial Analysis Intelligence Index. Competitor scores are against the models that were available at release time - Gemini 3 Pro and GPT-5.1.
| Benchmark | Claude Opus 4.5 | Gemini 3 Pro | GPT-5.1 |
|---|---|---|---|
| SWE-bench Verified | 80.9% | 76.2% | 76.3% |
| Terminal-Bench Hard | 44.0% | Not reported | Not reported |
| ARC-AGI-2 | 37.6% | 31.1% | 17.6% |
| GPQA Diamond | 87.0% | 91.9% | 88.1% |
| MMLU | 90.8% | 91.8% | 91.0% |
| MMMU | 80.7% | 81.0% | 85.4% |
| Prompt Injection ASR | 4.7% | 12.5% | 21.9% |
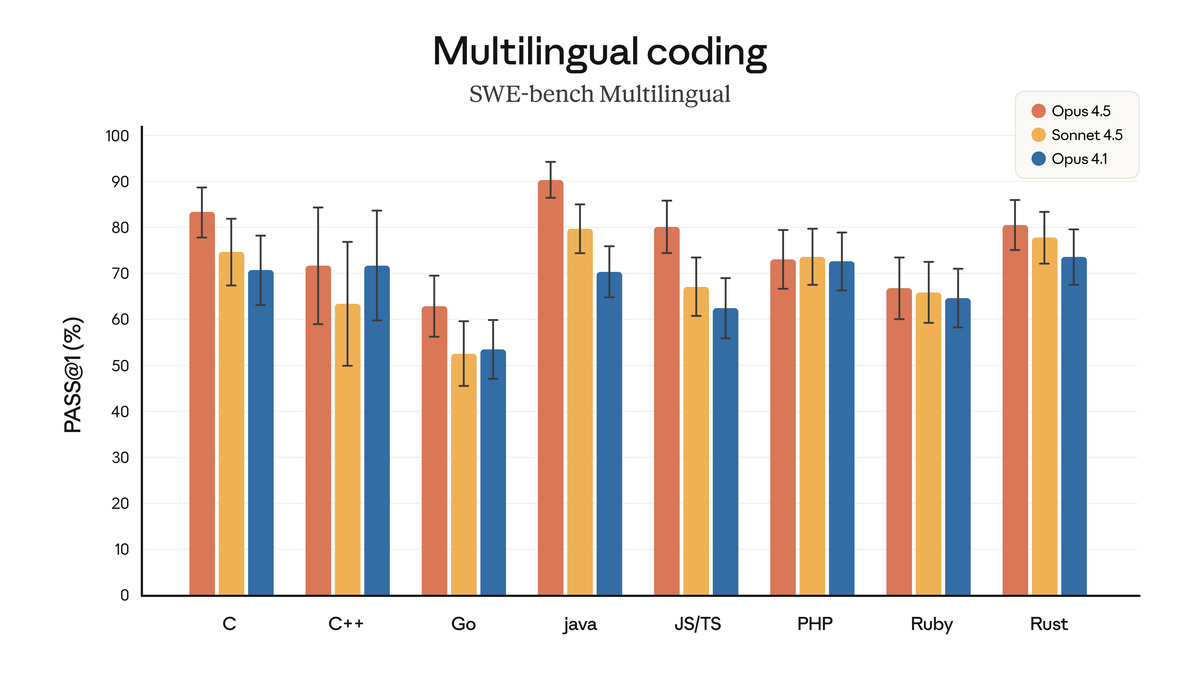 Multilingual SWE-bench (PASS@1) showing Opus 4.5 beating Sonnet 4.5 and Opus 4.1 across C, C++, Go, Java, JS/TS, PHP, Ruby, and Rust.
Source: anthropic.com
Multilingual SWE-bench (PASS@1) showing Opus 4.5 beating Sonnet 4.5 and Opus 4.1 across C, C++, Go, Java, JS/TS, PHP, Ruby, and Rust.
Source: anthropic.com
The coding results tell a clear story. The 80.9% SWE-bench Verified score and 44% Terminal-Bench Hard score held at the time of launch, though both have since been beaten by Claude Opus 4.7 and newer competitors. The ARC-AGI-2 result of 37.6% was a bigger jump - more than doubling GPT-5.1's score on a benchmark designed to test novel reasoning rather than pattern recall.
The weak spot is GPQA Diamond at 87.0%, where Gemini 3 Pro's 91.9% was a genuine gap. Scientific reasoning wasn't this model's primary design target. The prompt injection resistance number is worth noting for anyone building agentic systems: 4.7% attack success rate is substantially lower than the competition and reflects Anthropic's focus on making this model safe for use in automated pipelines where untrusted content can reach the model.
Check the agentic AI benchmarks leaderboard and coding benchmarks leaderboard for how Opus 4.5 compares to more recent releases.
Key Capabilities
Software Engineering and Agentic Coding
The model was purpose-built for long-horizon coding tasks. Anthropic's internal agent, Junie, showed that Opus 4.5 needed fewer steps to resolve bugs than Sonnet 4.5 and consumed fewer tokens per resolved issue. The Aider Polyglot score of 89.4% versus Sonnet 4.5's 78.8% is a 10.6 percentage point gap on a realistic multi-language coding benchmark.
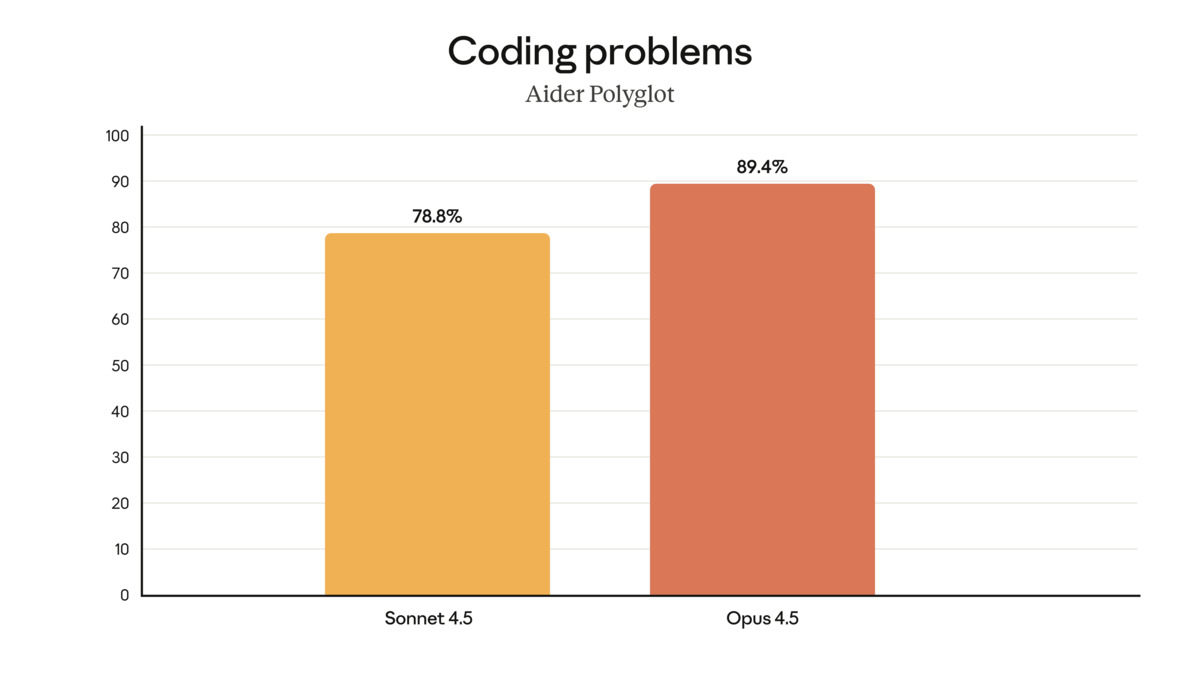 Aider Polyglot coding benchmark at launch - Opus 4.5 leads Sonnet 4.5 by 10.6 percentage points.
Source: anthropic.com
Aider Polyglot coding benchmark at launch - Opus 4.5 leads Sonnet 4.5 by 10.6 percentage points.
Source: anthropic.com
The Vending-Bench 2 result is also notable. Opus 4.5 scored $4,967.06 on a benchmark that simulates multi-step business workflows requiring sustained reasoning. Gemini 3 Pro scored $5,478.16, which means Gemini 3 Pro won that specific test, but the gap is narrow given how different the models' designs are.
Extended Thinking With Effort Control
The effort parameter maps to low (roughly 1K-2K thinking tokens), medium (4K-8K), and high (16K-32K). You can also pass a raw thinking_budget if you need fine-grained control. The model uses parallel tool calls during high-effort reasoning - it fires off multiple searches simultaneously during research tasks rather than executing them sequentially. For agentic pipelines with tool-intensive loops, the throughput difference is meaningful.
Previous thinking blocks are cached by default across turns. An agent that spent 20K tokens reasoning about a codebase in turn 1 doesn't pay for that reasoning again in turn 2 - it reads from the 1-hour cache at $0.50/M tokens instead of $5.00/M tokens. Combined with the Batch API's 50% discount, complex reasoning pipelines can run at a fraction of their surface cost.
Computer Use and Vision
Opus 4.5 supports computer use - controlling a desktop through screenshots and action sequences. It was positioned at the time as Anthropic's best model for computer use workflows. The MMMU score of 80.7% puts multimodal visual understanding slightly behind Gemini 3 Pro (81.0%) and well behind GPT-5.1 (85.4%), so vision-heavy tasks aren't a primary strength.
Pricing and Availability
At $5/$25 per million tokens, Opus 4.5 delivered Opus-class performance at one-third of what Opus 4.1 cost. That pricing was unchanged in Opus 4.6 and 4.7.
The model is available through Anthropic's direct API, Amazon Bedrock (ID: anthropic.claude-opus-4-5-20251101-v1:0), Google Vertex AI (ID: claude-opus-4-5@20251101), and Microsoft Azure (via Microsoft Foundry). The Claude web app routes to newer models by default.
Prompt caching has two TTL tiers on this model. The 5-minute cache costs 1.25x the base input price for writes and 0.1x for reads. The 1-hour cache costs 2x for writes and 0.1x for reads. For agents that send long system prompts on every call, the 1-hour TTL typically breaks even after 4-5 calls in quick succession.
Compared to Claude Opus 4.6 and 4.7 (both also $5/$25/M), Opus 4.5 has a smaller context window (200K vs 1M tokens) and lower max output (64K vs 128K tokens). If you're starting a new project, there's no pricing reason to choose 4.5 over 4.6 or 4.7.
Strengths
- Highest SWE-bench Verified score at its November 2025 launch
effortparameter gives practical control over reasoning cost vs. depth- Strong prompt injection resistance (4.7% ASR) compared to contemporary models
- 66% cheaper than Opus 4.1 with better performance
- 1-hour prompt caching TTL available for cost optimization in repetitive agentic loops
- Available on all major cloud platforms (AWS, GCP, Azure)
Weaknesses
- Superseded by Opus 4.6 and Opus 4.7, both at the same price but with 1M context and 128K output
- GPQA Diamond (87.0%) trails Gemini 3 Pro (91.9%) at launch - not the top choice for scientific reasoning
- MMMU vision score (80.7%) behind GPT-5.1 (85.4%)
- 200K context limit is a real constraint for very long document workflows
- No longer the recommended starting point per Anthropic's own docs
Related Coverage
- Claude Opus 4.6 - the next generation, adds 1M context and agent teams
- Claude Opus 4.7 - current Anthropic flagship, adds xhigh effort, 3x better vision, improved coding
- Agentic AI Benchmarks Leaderboard - track how Opus 4.5 compares to newer agentic models
- SWE-Bench Coding Agent Leaderboard - full SWE-bench rankings over time
- Coding Benchmarks Leaderboard - broader coding model comparisons
FAQ
Is Claude Opus 4.5 still available?
Yes. It's a legacy model available via the API under the pinned ID claude-opus-4-5-20251101. Anthropic's docs recommend migrating to Opus 4.7 for new projects.
How does the effort parameter work?
Pass effort: "low", effort: "medium", or effort: "high" in the extended thinking configuration. Medium effort uses about 76% fewer thinking tokens than unconstrained high-effort mode while matching prior top-tier performance.
What is the price for Claude Opus 4.5?
$5.00 per million input tokens and $25.00 per million output tokens. Prompt caching and Batch API reduce costs further. Identical pricing to Opus 4.6 and 4.7.
How does Opus 4.5 compare to Opus 4.6?
Opus 4.6 added a 1M token context window (vs 200K), 128K max output (vs 64K), and agent teams for multi-model coordination. Both models are priced the same. Opus 4.6 is the better default unless you have prompts already tuned to 4.5.
What is the model ID for Claude Opus 4.5?
The pinned Claude API ID is claude-opus-4-5-20251101. The alias claude-opus-4-5 resolves to this snapshot.
Sources:
- Introducing Claude Opus 4.5 - Anthropic
- Claude Models Overview - Anthropic Docs
- Claude Opus 4.5 Benchmarks - Vellum
- Claude Opus 4.5 Benchmarks and Analysis - Artificial Analysis
- Claude Opus 4.5 System Card - Anthropic
- Claude Opus 4.5 - OpenRouter
- Claude Opus 4.5 Benchmarks, Pricing & Context Window - LLM Stats
Last updated
✓ Last verified May 18, 2026
