Arcee Trinity
Arcee Trinity-Large-Thinking is a 400B sparse MoE open-source reasoning model that ranks #2 on PinchBench at $0.85/M output tokens, 28x cheaper than Claude Opus 4.6.

Arcee AI shipped Trinity-Large-Thinking on April 1, 2026 - the reasoning-capable variant of its 400B sparse Mixture-of-Experts model. The base Trinity-Large-Preview had launched in late January, but the Thinking release is what put Arcee on the short list of labs building frontier-tier open models. It holds the #2 spot on PinchBench, an agent-focused evaluation run by Kilo that tests real-world agentic task performance, trailing only Claude Opus 4.6 among all public models.
TL;DR
- #2 on PinchBench (91.9), seconds behind Claude Opus 4.6's 93.3 - at 28x lower cost
- 398B params, 13B active per token; 256K context (512K extended); Apache 2.0 license
- Designed for long-horizon agents - better instruction coherence over multi-turn tool calls than the Preview variant
Arcee is a Miami-based startup of roughly 39 people, founded in 2023 by Jacob Solawetz, Brian Benedict, and Mark McQuade. They trained Trinity entirely in-house, spending around $20 million total on compute, salaries, and data - a figure that looks implausible for a 400B model until you factor in the sparse MoE architecture. With only 4 of 256 experts active per token, effective compute per forward pass is closer to a 13B dense model than a 400B one. The result is inference throughput 2-3x faster than comparably-sized dense models on identical hardware.
Key Specifications
| Specification | Details |
|---|---|
| Provider | Arcee AI |
| Model Family | Trinity |
| Parameters | 398B total, 13B active per token |
| Architecture | Sparse MoE, 256 experts, 4 active per token |
| Context Window | 256K tokens (512K extended) |
| Input Price | $0.22/M tokens |
| Output Price | $0.85/M tokens |
| Release Date | 2026-01-27 (Preview), 2026-04-01 (Thinking) |
| License | Apache 2.0 |
| Training Data | 17 trillion tokens |
The model runs on vLLM, SGLang, llama.cpp, LM Studio, and HuggingFace Transformers. Weights are on Hugging Face under arcee-ai/Trinity-Large-Thinking. OpenRouter also hosts it at $0.22/$0.85 per million tokens with a 262K context window in that deployment.
Benchmark Performance
The two Trinity variants serve different use cases: Preview is the lightly post-trained baseline suitable for general deployment; Thinking adds internal chain-of-thought reasoning before responding and is the right choice for complex agents and tasks.
Trinity-Large-Preview vs Llama 4 Maverick
| Benchmark | Trinity-Large-Preview | Llama 4 Maverick |
|---|---|---|
| MMLU | 87.2 | 85.5 |
| MMLU-Pro | 75.2 | 80.5 |
| GPQA Diamond | 63.3 | 69.8 |
| AIME 2025 | 24.4 | 19.3 |
The preview model lands roughly at Llama 4 Maverick level on academic evals, trading wins and losses depending on the task. Arcee's own framing was accurate: "roughly in line with Llama-4-Maverick's Instruct model." The MMLU edge is real; the GPQA and MMLU-Pro gaps are also real.
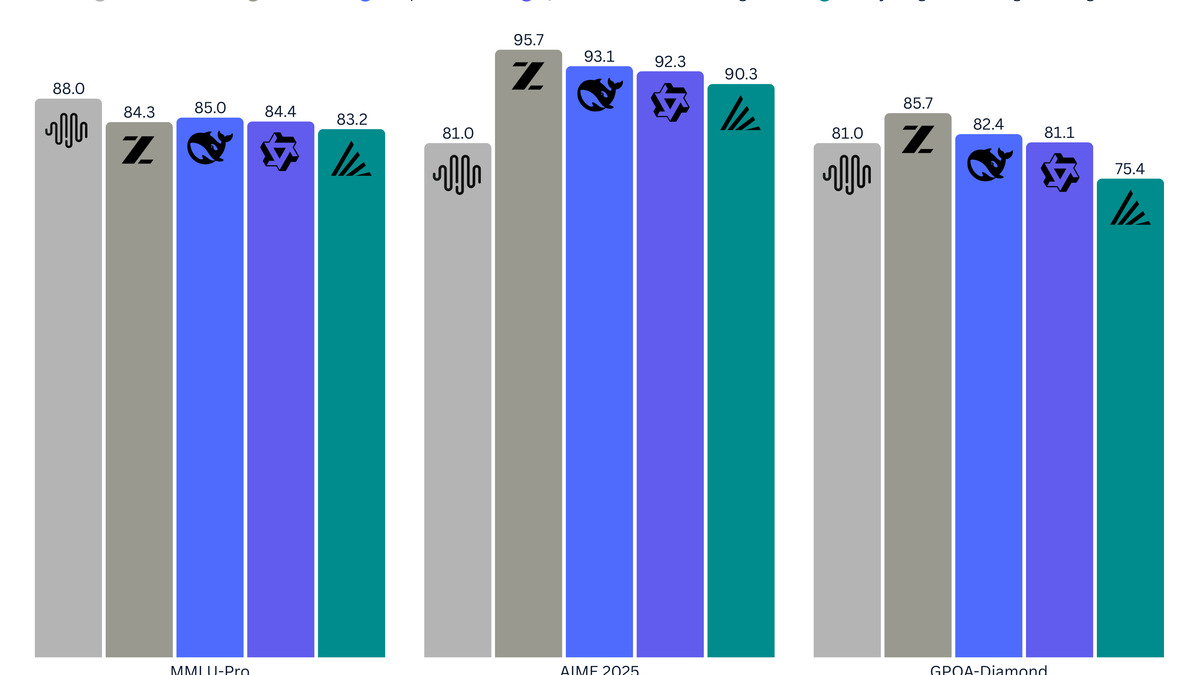 Trinity-Large-Preview benchmark scores across key academic evaluations.
Source: arcee.ai
Trinity-Large-Preview benchmark scores across key academic evaluations.
Source: arcee.ai
Trinity-Large-Thinking vs Frontier Models
| Benchmark | Trinity-Large-Thinking | Claude Opus 4.6 | GLM-5 | MiniMax-M2.5 | Kimi-K2.5 |
|---|---|---|---|---|---|
| PinchBench | 91.9 | 93.3 | 86.4 | 89.8 | 84.8 |
| GPQA Diamond | 76.3 | 89.2 | 81.6 | 86.2 | 86.9 |
| MMLU-Pro | 83.4 | 89.1 | 85.8 | 80.8 | 87.1 |
| AIME 2025 | 96.3 | 99.8 | 93.3 | 80.0 | 96.3 |
| SWE-bench Verified | 63.2 | 75.6 | 72.8 | 75.4 | 70.8 |
| LiveCodeBench | 98.2 | N/A | N/A | N/A | N/A |
| IFBench | 52.3 | 53.1 | 72.3 | 75.7 | 70.2 |
The PinchBench result is the headline number and it's genuine. On agentic task completion, Trinity-Thinking sits within 1.4 points of Claude Opus 4.6 while costing 28x less per million output tokens. That gap matters for anyone running agent workloads at volume.
The weaknesses are equally real. GPQA Diamond at 76.3 is 13 points behind Claude Opus 4.6, and SWE-bench Verified at 63.2 is a full 12 points back. Instruction-following (IFBench: 52.3) is the biggest gap - both GLM-5 and Kimi-K2.5 beat it by more than 18 points there. If your workload involves precise format adherence or structured output at high volume, the Thinking model will frustrate.
Check the agentic AI benchmarks leaderboard for how Trinity ranks across the full agent benchmark suite.
Key Capabilities
Trinity-Large-Thinking was built for agents, not chat. Arcee trained it with long-horizon planning in mind: stable context coherence across hundreds of tool calls, clean multi-turn interaction without state drift, and structured reasoning that stays consistent through extended agent loops. The Thinking prefix keeps the model's intermediate steps in context so downstream tool calls can reference earlier reasoning rather than starting cold each turn.
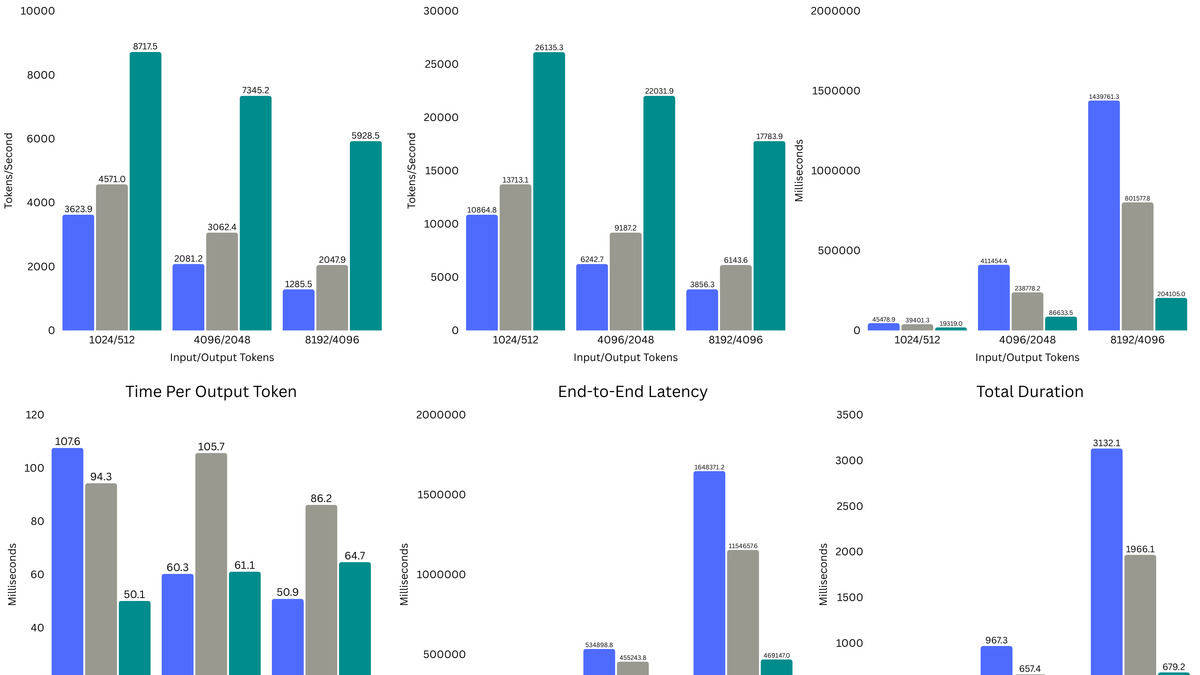 Trinity hits 2-3x higher inference throughput than comparably-sized dense models.
Source: arcee.ai
Trinity hits 2-3x higher inference throughput than comparably-sized dense models.
Source: arcee.ai
The context window is 256K in standard deployments, but Arcee's technical report shows 0.976 accuracy on needle-in-a-haystack tests at 512K tokens - beyond the training distribution. That extended window is relevant for agent tasks where tool outputs build up across many steps. OpenRouter caps it at 262K; self-hosted deployments on vLLM can go further.
LiveCodeBench at 98.2 is the model's strongest single number. Competitive coding performance is consistent with the training emphasis on synthetic code and math data - over 8 trillion of the 17 trillion training tokens were synthetic. The model trained across three phases with the Muon optimizer for hidden layers, a choice Arcee's report notes helps with MoE training stability.
"Getting here took difficult technical work, hard calls, and more than a few moments where the easy thing would have been to lower the ambition." - Arcee AI
From launch through early March 2026, OpenRouter served 3.37 trillion Trinity tokens, making it the most-used open model in the US and #4 globally by traffic. That adoption rate at free-preview pricing isn't directly transferable to paid-tier economics, but it confirms the model runs reliably at scale.
Pricing and Availability
Trinity comes in three variants with different tradeoffs:
- Trinity-Large-Preview: Free on OpenRouter (128K context, 8-bit quantization). Good for evaluation and low-stakes workloads.
- Trinity-Large-Base: Full pretraining checkpoint at 17T tokens. No post-training, aimed at researchers building their own fine-tunes.
- Trinity-Large-Thinking: $0.22/M input, $0.85/M output on OpenRouter. This is the production reasoning model.
Weights for all three are on Hugging Face under Apache 2.0 - you can download and run them commercially with no restrictions. vLLM is the recommended serving framework. For the Thinking variant, Arcee recommends temperature 0.3 and keeping thinking tokens in context for multi-turn conversations.
The cost-per-token story is straightforward. At $0.90/M output (the figure Arcee uses in its own comparisons), Trinity-Thinking costs roughly 96% less than Claude Opus 4.6 at $25/M. That's not a marginal difference - it's an order of magnitude. For agentic workloads where output token counts run into the tens of millions per day, that gap determines whether a product is financially viable.
See the cost efficiency leaderboard for a full comparison of price-per-point across major models.
Strengths and Weaknesses
Strengths
- #2 on PinchBench among all public models - competitive with closed frontier models on agentic tasks
- 28x lower cost per output token than Claude Opus 4.6
- Apache 2.0 license with full weight access - no usage restrictions
- 2-3x faster inference throughput than comparable dense models
- 256K context with reliable 512K extension
- LiveCodeBench at 98.2 is among the highest scores for any open model
Weaknesses
- GPQA Diamond at 76.3 is 13 points behind Claude Opus 4.6 - not a substitute for hard science reasoning
- SWE-bench Verified at 63.2 trails the frontier by 12+ points - coding agents hitting complex real-world repos will see the gap
- Instruction-following (IFBench: 52.3) is a genuine weak spot - GLM-5 and Kimi-K2.5 are substantially better
- No official fine-tuning infrastructure yet - downstream customization is community-driven
- OpenRouter preview pricing may not reflect long-term production costs
Related Coverage
- Llama 4 Maverick - Meta's comparable open-weight MoE and Trinity's primary base-model benchmark target
- Open-Source LLM Leaderboard - full rankings across open models including Trinity
- Agentic AI Benchmarks Leaderboard - PinchBench and agent eval context
- Coding Benchmarks Leaderboard - SWE-bench and LiveCodeBench context
FAQ
What is Trinity-Large-Thinking best for?
Long-horizon AI agents requiring multi-turn tool use, planning, and context coherence. Its #2 PinchBench score reflects real agentic capability at 28x lower cost than Claude Opus 4.6, making it practical for high-volume agent deployments.
How does Trinity compare to Llama 4 Maverick?
The Preview variant lands roughly at Maverick level on academic benchmarks. Trinity-Thinking is substantially stronger than Maverick on reasoning tasks, though Llama 4 Maverick has better instruction following.
Can Trinity be self-hosted?
Yes. All three variants (Preview, Base, Thinking) are available on Hugging Face under Apache 2.0. Compatible with vLLM, SGLang, llama.cpp, and LM Studio. Arcee's technical report recommends using Muon-based serving configs for best MoE routing efficiency.
What's the difference between the Preview and Thinking variants?
Preview is a lightly post-trained instruction model suitable for general tasks. Thinking adds internal chain-of-thought reasoning before responding, improving complex reasoning and multi-step planning at the cost of higher output token counts.
Is Trinity free to use commercially?
Yes. The Apache 2.0 license allows commercial use, modification, and distribution with no royalties or access restrictions. This applies to all Trinity variants including the full base checkpoint.
Sources:
- Arcee AI - Trinity Large Thinking Blog Post
- Arcee AI - Trinity Large Blog Post
- Trinity Large: Technical Report (arXiv 2602.17004)
- Trinity-Large-Thinking on OpenRouter
- Trinity-Large-Thinking on Hugging Face
- Neurohive: Trinity matches Claude Opus 4.6 at 28x lower cost
- MarkTechPost: Arcee AI releases Trinity-Large-Thinking
- Arcee AI Documentation: Trinity-Large-Thinking
Last updated
✓ Last verified April 16, 2026
