Migrating from OpenAI API to Anthropic API
A practical guide to switching from OpenAI's chat completions to Anthropic's Messages API, covering endpoint mapping, tool use differences, and pricing.

TL;DR
- Yes, you can switch - Anthropic offers an OpenAI SDK compatibility layer for quick testing
- System message handling, image inputs, tool calling schemas, and temperature handling all change
- You gain prompt caching (up to 90% savings), adaptive thinking on Opus 4.7, and PDF support
- Medium difficulty, 2-4 hours typical - but Opus 4.7 adds breaking API changes that require code updates
Why Switch from OpenAI to Anthropic?
Developers are increasingly moving workloads to the Anthropic API for a few concrete reasons. Claude Opus 4.7 - released April 16, 2026 - is Anthropic's current flagship, with a standout jump in agentic coding performance and high-resolution vision (images up to 3.75 megapixels, more than triple prior models). Its adaptive thinking mode lets Claude decide when and how much extended reasoning to apply, without you manually specifying token budgets. Prompt caching can cut costs by up to 90% on repeated context, which matters at scale. And features like native PDF processing and citations aren't available through OpenAI's API at all.
Still, this isn't a drop-in swap. The request format is different, system messages work differently, and tool calling uses its own schema. If you've fine-tuned prompts specifically for GPT-4o or GPT-5, expect to spend time adjusting them for Claude.
Anthropic does offer an OpenAI SDK compatibility layer that lets you point the OpenAI Python or TypeScript SDK at Anthropic's endpoint. It's useful for quick comparisons, but it strips out Claude-specific features like prompt caching, extended thinking, and structured outputs. For production, you'll want the native API.
Feature Parity Table
| Feature | OpenAI | Anthropic | Notes |
|---|---|---|---|
| Chat completions | POST /v1/chat/completions | POST /v1/messages | Different request/response format |
| Streaming | stream: true (SSE) | stream: true (SSE) | Direct equivalent, different event names |
| System prompt | role: "system" in messages array | Top-level system parameter | Anthropic uses a single system block |
| Function/tool calling | tools[] with functions | tools[] with input_schema | Different schema structure |
| Structured output | response_format with JSON schema | output_config or tool strict: true | Both support strict validation |
| Image input | URL or base64 in content array | Base64 or URL in content array | Both now support URLs |
| PDF input | Not supported | Native DocumentBlockParam | Anthropic-only feature |
| Prompt caching | Not available | cache_control parameter | Up to 90% input cost savings |
| Adaptive thinking | Not available | thinking: {type: "adaptive"} | Opus 4.7: only supported mode. Also works on Sonnet 4.6, Opus 4.6 |
| Extended thinking (legacy) | Not available | thinking: {type: "enabled", budget_tokens: N} | Deprecated on Sonnet/Opus 4.6; removed on Opus 4.7 (400 error) |
| Temperature / sampling | 0-2 range | 0-1 range (Sonnet 4.6, Haiku 4.5); rejected on Opus 4.7 | Breaking change - omit entirely when targeting Opus 4.7 |
| Embeddings | POST /v1/embeddings | Not available | Use a separate provider |
| Audio input | Supported | Not supported | OpenAI-only feature |
| Batch processing | Batch API (50% discount) | Batch API (50% discount) | Both offer async batching |
 Switching APIs means updating more than just the endpoint URL - message structure, tool schemas, and thinking parameters all differ.
Source: unsplash.com
Switching APIs means updating more than just the endpoint URL - message structure, tool schemas, and thinking parameters all differ.
Source: unsplash.com
API Mapping
The core difference is structural. OpenAI wraps everything in a chat/completions envelope with a choices array. Anthropic returns a message object with a content array of typed blocks.
Basic Chat Completion
OpenAI:
from openai import OpenAI
client = OpenAI(api_key="sk-...")
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain quantum computing in two sentences."}
],
max_tokens=256,
temperature=0.7
)
print(response.choices[0].message.content)
Anthropic:
import anthropic
client = anthropic.Anthropic(api_key="sk-ant-...")
response = client.messages.create(
model="claude-sonnet-4-6",
system="You are a helpful assistant.",
messages=[
{"role": "user", "content": "Explain quantum computing in two sentences."}
],
max_tokens=256,
temperature=0.7
)
print(response.content[0].text)
Three things changed. The system prompt moved from the messages array to a top-level system parameter. The response comes back as response.content[0].text instead of response.choices[0].message.content. And the model name uses Anthropic's naming scheme.
Streaming
OpenAI:
stream = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Write a haiku about APIs."}],
stream=True
)
for chunk in stream:
delta = chunk.choices[0].delta.content
if delta:
print(delta, end="")
Anthropic:
with client.messages.stream(
model="claude-sonnet-4-6",
messages=[{"role": "user", "content": "Write a haiku about APIs."}],
max_tokens=100
) as stream:
for text in stream.text_stream:
print(text, end="")
Anthropic's Python SDK provides a .stream() context manager that yields text directly, which is actually cleaner than parsing delta objects. Under the hood, both use SSE, but the event types differ - Anthropic sends content_block_delta events while OpenAI sends chat.completion.chunk events.
Tool Calling
This is where the biggest differences show up.
OpenAI:
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "What's the weather in Paris?"}],
tools=[{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather for a city",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "City name"}
},
"required": ["city"]
}
}
}]
)
tool_call = response.choices[0].message.tool_calls[0]
print(tool_call.function.name, tool_call.function.arguments)
Anthropic:
response = client.messages.create(
model="claude-sonnet-4-6",
messages=[{"role": "user", "content": "What's the weather in Paris?"}],
max_tokens=256,
tools=[{
"name": "get_weather",
"description": "Get current weather for a city",
"input_schema": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "City name"}
},
"required": ["city"]
}
}]
)
tool_block = next(b for b in response.content if b.type == "tool_use")
print(tool_block.name, tool_block.input)
Two structural differences matter here. OpenAI nests tools under type: "function" with a function key containing parameters. Anthropic puts name, description, and input_schema at the top level of each tool. Second, OpenAI returns tool calls as a separate tool_calls array on the message, while Anthropic includes them as tool_use content blocks in the same content array as text.
Image Input
OpenAI:
response = client.chat.completions.create(
model="gpt-4o",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "What's in this image?"},
{"type": "image_url", "image_url": {"url": "https://example.com/photo.jpg"}}
]
}]
)
Anthropic:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=256,
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "What's in this image?"},
{"type": "image", "source": {"type": "url", "url": "https://example.com/photo.jpg"}}
]
}]
)
Both APIs now support image URLs directly. Anthropic also supports base64 encoding with "type": "base64" and a media_type field. One constraint to watch: Anthropic rejects images larger than 8000x8000 pixels, and if you send more than 20 images per request, each must be under 2000x2000.
Pricing Impact
Pricing depends heavily on which models you're comparing. Both providers have updated their lineups since early 2026 - OpenAI's current flagship family is the GPT-5.4 series. Here are the most common matchups as of April 2026:
| Use Case | OpenAI Model | Price (in/out per 1M tokens) | Claude Model | Price (in/out per 1M tokens) |
|---|---|---|---|---|
| Flagship | GPT-5.4 | $2.50 / $15.00 | Claude Opus 4.7 | $5.00 / $25.00 |
| Mid-tier | GPT-5.4 mini | $0.75 / $4.50 | Claude Sonnet 4.6 | $3.00 / $15.00 |
| Fast/cheap | GPT-5.4 nano | $0.20 / $1.25 | Claude Haiku 4.5 | $1.00 / $5.00 |
For a workload processing 10 million input tokens and 2 million output tokens per month at the mid-tier:
- GPT-5.4 mini: (10 x $0.75) + (2 x $4.50) = $16.50/month
- Claude Sonnet 4.6: (10 x $3.00) + (2 x $15.00) = $60.00/month
Claude Sonnet costs roughly 3.6x more in this base-rate scenario. Anthropic's prompt caching narrows that gap for workloads with repeated context - cache hits cost 10% of the standard input price. A workload where 70% of input tokens are cached brings Claude Sonnet's effective cost down to around $41/month, while GPT-5.4 mini with caching drops to roughly $12/month. OpenAI is still cheaper, but the gap is smaller, and the trade-off may be worth it for specific features like adaptive thinking, PDF support, or longer output limits.
Both providers offer 50% discounts through their batch APIs. Claude Sonnet 4.6 and Opus 4.7 also support up to 300k output tokens per request through the Batch API with the output-300k-2026-03-24 beta header - useful for very long generation tasks.
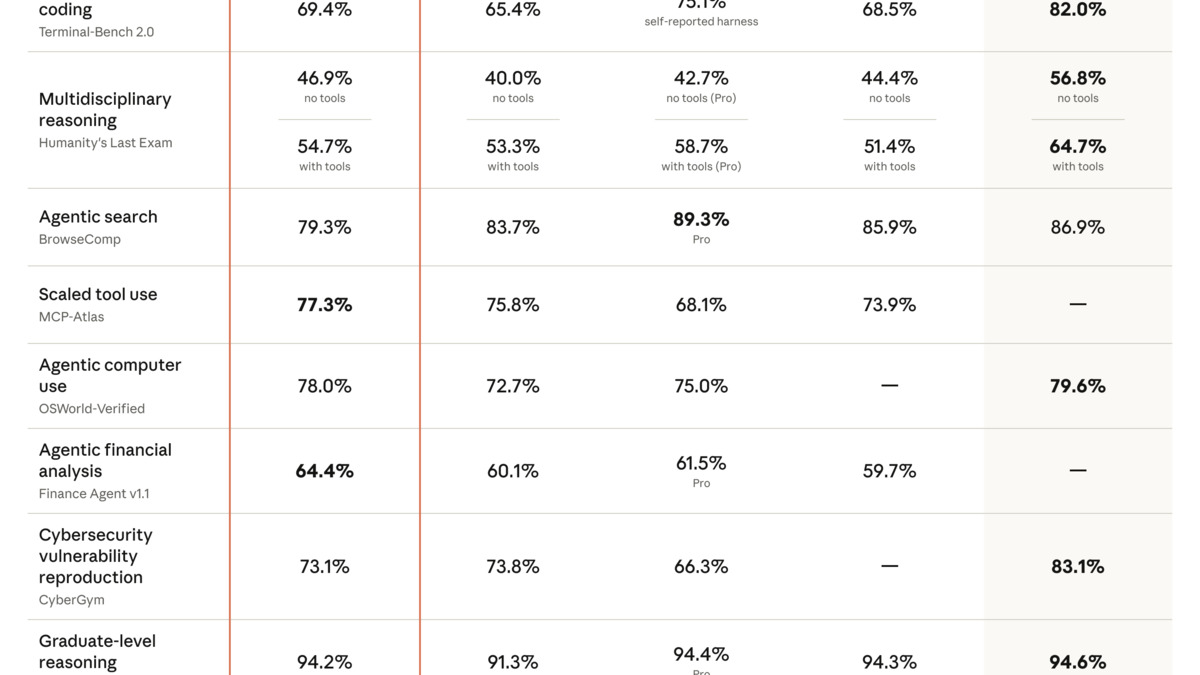 Claude Opus 4.7 benchmark results from Anthropic's April 2026 release announcement, showing gains in coding, vision, and reasoning tasks.
Source: anthropic.com
Claude Opus 4.7 benchmark results from Anthropic's April 2026 release announcement, showing gains in coding, vision, and reasoning tasks.
Source: anthropic.com
Known Gotchas
System messages get concatenated. If your OpenAI code places system messages at multiple points in the conversation, Anthropic will hoist and concatenate them all into one system block at the start. This can break prompts that rely on mid-conversation system instructions.
max_tokensis required. OpenAI defaults to a model-specific maximum if you omitmax_tokens. Anthropic requires it explicitly - you'll get an error if it's missing.No
response_formatfor JSON mode. OpenAI'sresponse_format: { type: "json_object" }doesn't have a direct equivalent. Use Anthropic's structured outputs (viaoutput_configwith a JSON schema) or tool use withstrict: trueinstead.Temperature range differs. OpenAI accepts temperatures from 0 to 2. Anthropic caps at 1.0 and silently clamps anything higher. If you were using temperature 1.5 for creative tasks, your outputs will be less varied on Claude.
No embeddings endpoint. Anthropic doesn't offer an embeddings API. If your pipeline creates embeddings, you'll need to keep OpenAI for that or switch to an alternative like Voyage AI or a self-hosted solution.
nparameter must be 1. OpenAI lets you request multiple completions per call (e.g.,n=3). Anthropic always returns exactly one response. You'll need to make separate API calls if you want multiple generations.Token counting uses different tokenizers. The same text will produce different token counts between OpenAI (tiktoken) and Anthropic. Don't assume your existing token estimates will transfer directly.
Role alternation is strict. Anthropic requires messages to alternate between
userandassistantroles. OpenAI is more lenient about consecutive messages from the same role. You may need to merge adjacent user messages before sending.Opus 4.7 rejects temperature, top_p, and top_k. Starting with
claude-opus-4-7, passing any non-default value for these sampling parameters returns a 400 error. This is a hard break - code that setstemperature=0.7will fail right away. Remove these parameters from your requests and use prompting to guide output style instead.claude-sonnet-4-6andclaude-haiku-4-5still accept temperature values up to 1.0.budget_tokensis removed on Opus 4.7. The extended thinking syntaxthinking: {type: "enabled", budget_tokens: N}no longer works onclaude-opus-4-7- it returns a 400 error. Switch tothinking: {type: "adaptive"}and use theeffortparameter (low,medium,high,xhigh,max) to guide how much reasoning Claude does. If you need predictable cost control, pair adaptive thinking with a firmmax_tokenscap.Opus 4.7 uses a new tokenizer. The same text can consume 1.0x to 1.35x as many tokens on Opus 4.7 compared to earlier models, depending on content. If you have tight
max_tokensbudgets or per-request cost caps, test with your actual content before a production migration - you may hitstop_reason: "max_tokens"more often than expected.thinking.displaydefaults to "omitted" on Opus 4.7. On Opus 4.6, thinking blocks default to"summarized"- you see the reasoning content in the response. On Opus 4.7, the default changed to"omitted"- thinking blocks appear in the stream but thethinkingfield is empty. To restore visible thinking text, explicitly setthinking: {type: "adaptive", display: "summarized"}.
FAQ
Can I use the OpenAI SDK with Anthropic's API?
Yes. Set base_url to https://api.anthropic.com/v1/ and use your Anthropic API key. But this compatibility layer doesn't support prompt caching, structured outputs, or extended thinking.
Will my OpenAI prompts work without changes?
Basic prompts usually transfer well, but heavily optimized prompts will need tuning. Anthropic recommends their Console's prompt improver as a starting point for adaptation.
Is there a compatibility layer for production use?
The OpenAI SDK compatibility layer is for testing and evaluation only. Anthropic recommends their native SDK for production workloads to access all features.
How do I handle the missing embeddings endpoint?
Use a dedicated embeddings provider like Voyage AI, Cohere, or run an open-source model. See our embeddings guide for options.
Does Anthropic support fine-tuning?
Not through their public API as of April 2026. If you rely on OpenAI fine-tuned models, you'll need to reproduce that behavior through prompt engineering or explore Anthropic's enterprise offerings.
Does switching to Opus 4.7 require code changes beyond swapping the model ID?
Yes. Opus 4.7 removes temperature, top_p, and top_k (pass them and get a 400 error), and drops extended thinking with budget_tokens. Switch to thinking: {type: "adaptive"} and remove sampling params before changing the model ID.
What about rate limits?
Both providers use token-based and request-based rate limits that scale with your usage tier. Check Anthropic's rate limits documentation for current thresholds.
Sources:
- Anthropic Messages API Reference
- Anthropic OpenAI SDK Compatibility
- Anthropic Tool Use Documentation
- Anthropic Vision Documentation
- Anthropic Streaming Documentation
- Anthropic Pricing
- Anthropic Models Overview
- Anthropic Adaptive Thinking Documentation
- Anthropic Migration Guide to Claude Opus 4.7
- Introducing Claude Opus 4.7 - Anthropic Blog
- OpenAI API Reference
- OpenAI Pricing
- OpenAI Function Calling Guide
Last updated
✓ Last verified April 20, 2026
