GAIA Benchmark Leaderboard: Best AI Agents May 2026
Rankings of the best AI models and agent frameworks on the GAIA benchmark, which tests real-world multi-step tasks requiring web browsing, tool use, and multi-hop reasoning.

The GAIA benchmark has a simple premise: can an AI assistant actually complete real-world tasks? Not answer questions about tasks, not describe the steps needed - actually do the work. When Meta, HuggingFace, and AutoGPT researchers introduced it in late 2023, the answer was a clear no. GPT-4 with plugins scored 15%. Humans scored 92%.
That gap has narrowed substantially since. Top-performing agent systems now reach 74-75% on the public validation set, and purpose-built multi-agent platforms are clearing 90% on the full private test. The best general AI assistants are now genuinely capable on the complex, tool-heavy tasks that define real productivity work.
What makes GAIA analytically useful is what it shows about scaffolding. The same underlying model can score 44% when called directly and 74% inside a well-built agent framework. If you're selecting models for agentic work, that 30-point swing dwarfs most model-vs-model differences. GAIA doesn't just rank models - it ranks systems. For 2026 deployments, that's the right framing.
TL;DR
- Claude Sonnet 4.5 with HAL Generalist leads at 74.55%, Anthropic holds all top 6 HAL positions
- The scaffold matters as much as the model - same model scores ~30 points higher in HAL vs. bare API call
- Best value: o4-mini Low with HAL at 58.18% for $73 per full run vs. $666 for Claude Opus 4 High
- Current 2026 frontier models (no framework) top out at 52.3% bare
What GAIA Measures
GAIA (General AI Assistants) contains 466 human-authored questions split across three difficulty levels. Every question has a single, unambiguous, verifiable answer - no partial credit, no subjective grading.
Three Levels of Difficulty
Level 1 requires at most one or two tools and a short reasoning chain. Example: "What was the enrollment count of the H. pylori acne trial from Jan-May 2018, per the NIH website?" One search, one number. Good models handle these reliably.
Level 2 chains multiple tools and demands several intermediate reasoning steps. Example: "Based on BLS.gov data, what was the unemployment gap between men and women aged 20+ in June 2009?" That's web navigation, data extraction, and arithmetic - three steps minimum.
Level 3 problems are truly hard. Tasks at this level might require identifying fruits in a 2008 painting, cross-referencing those against a 1949 ocean liner breakfast menu, and returning a clockwise-ordered comma-separated list. These chain 20+ steps and test whether an agent can maintain state across a complex long-horizon task.
Human performance: 92% overall. Level 3 remains above 70% for humans; for most AI agents, it stays below 55%.
The HAL Evaluation Framework
The Princeton HAL (Holistic Agent Leaderboard) is the most analytically rigorous GAIA evaluation. It runs agents through a standardized harness, tracks token counts and API costs per run, and reports accuracy at each difficulty level separately. HAL evaluates against the public validation set of 165 questions. Results show Pareto-best combinations - the configurations that dominate on the accuracy-vs-cost trade-off curve.
One important note from Princeton's team: as of early 2026, they paused adding new models to focus on reliability measurement rather than raw accuracy tracking. The top HAL entries represent the best-characterized model+framework combinations from late 2025, not the newest 2026 models.
HAL Standardized Rankings
All results below use the HAL Generalist or HF Open Deep Research frameworks for direct comparison. The cost column is total API spend to run all 165 validation questions.
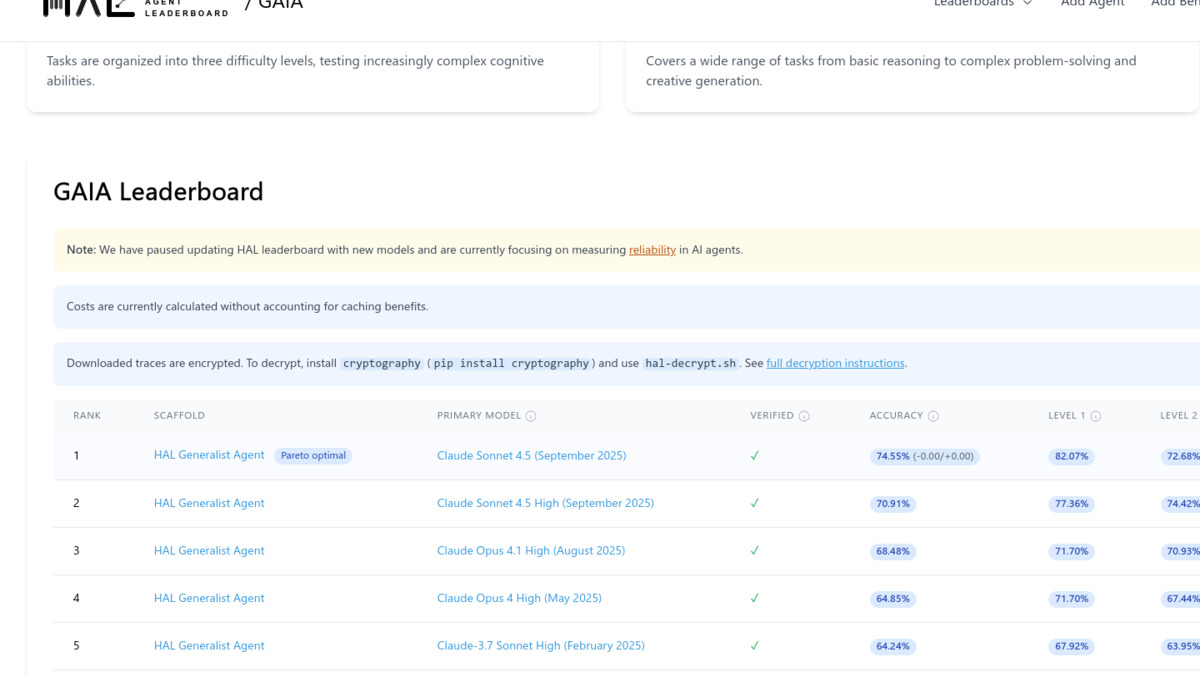 The HAL leaderboard uses standardized scaffolding to compare models fairly. Claude Sonnet 4.5 leads the Pareto-optimal frontier as the highest-accuracy lowest-cost combination.
Source: hal.cs.princeton.edu
The HAL leaderboard uses standardized scaffolding to compare models fairly. Claude Sonnet 4.5 leads the Pareto-optimal frontier as the highest-accuracy lowest-cost combination.
Source: hal.cs.princeton.edu
| Rank | Framework | Model | Overall | L1 | L2 | L3 | Cost |
|---|---|---|---|---|---|---|---|
| 1 | HAL Generalist | Claude Sonnet 4.5 (Sep 2025) | 74.55% | 82.07% | 72.68% | 65.39% | $178 |
| 2 | HAL Generalist | Claude Sonnet 4.5 High | 70.91% | 77.36% | 74.42% | 46.15% | $180 |
| 3 | HAL Generalist | Claude Opus 4.1 High (Aug 2025) | 68.48% | 71.70% | 70.93% | 53.85% | $562 |
| 4 | HAL Generalist | Claude Opus 4 High (May 2025) | 64.85% | 71.70% | 67.44% | 42.31% | $666 |
| 5 | HAL Generalist | Claude 3.7 Sonnet High | 64.24% | 67.92% | 63.95% | 57.69% | $122 |
| 6 | HAL Generalist | Claude Opus 4.1 | 64.24% | 71.70% | 66.28% | 42.31% | $642 |
| 7 | HF Open Deep Research | GPT-5 Medium (Aug 2025) | 62.80% | 73.58% | 62.79% | 38.46% | $360 |
| 8 | HAL Generalist | GPT-5 Medium (Aug 2025) | 59.39% | 67.92% | 58.14% | 46.15% | $105 |
| 9 | HAL Generalist | o4-mini Low (Apr 2025) | 58.18% | 71.70% | 51.16% | 53.85% | $73 |
| 10 | HF Open Deep Research | Claude Opus 4 | 57.58% | 66.04% | 56.98% | 42.31% | $1,686 |
| 11 | HAL Generalist | Claude 3.7 Sonnet | 56.36% | 62.26% | 55.81% | 46.15% | $131 |
| 12 | HAL Generalist | Claude Haiku 4.5 (Oct 2025) | 56.36% | 62.26% | 51.16% | 61.54% | $131 |
| 13 | HF Open Deep Research | o4-mini High | 55.76% | 69.81% | 51.16% | 42.31% | $185 |
| 14 | HAL Generalist | o4-mini High | 54.55% | 60.38% | 53.49% | 46.15% | $59 |
| 15 | HF Open Deep Research | GPT-4.1 (Apr 2025) | 50.30% | 58.49% | 50.00% | 34.62% | $110 |
"High" denotes extended thinking or higher compute mode. Costs cover the full 165-question validation set at listed API rates. GPT-5 refers to the base Aug 2025 release, separate from GPT-5.2/5.4.
Key Takeaways
Anthropic Holds Every Top Position
The first six entries in the HAL table are all Claude. That's not a narrow win - the gap between rank 1 (74.55%) and rank 7 (62.80%) spans nearly 12 percentage points, and every entry in that gap is an Anthropic model.
Claude models respond well to the HAL framework's tool routing and context management, which aligns with Claude's strength in long-horizon instruction following (see our Claude Sonnet 4.6 review for hands-on assessment of the current generation). Claude Opus 4 and Opus 4.1 are on the HAL leaderboard but represent older checkpoints; our Claude Opus 4.7 review covers the latest Opus generation.
The Claude 3.7 Sonnet High configuration at rank 5 earns special mention. It matches the Opus 4 configurations at 64.24% overall while costing $122 per run versus $642-$666 for the Opus entries. For teams that need Opus-level GAIA performance on a constrained budget, 3.7 Sonnet High is worth testing before committing to Opus.
The 30-Point Framework Effect
The most consequential finding in the GAIA data isn't which model wins. It's the magnitude of the scaffold effect.
Claude Sonnet 4.6 (the current Sonnet generation) scores 45.5% when called directly without a framework. The HAL evaluation of the earlier Claude Sonnet 4.5 reaches 74.55%. That's roughly 30 points from scaffolding alone - structured tool routing, retry logic, context pruning, and error recovery that a direct API call doesn't include.
The scaffold adds more performance than upgrading between model generations. A well-built agent loop running an older model beats a newer model called raw.
The HF Open Deep Research framework shows the same pattern: it scores 62.80% on GPT-5 Medium versus HAL's 59.39% on the same model, though at $360 vs. $105. Both frameworks beat bare calling by a wide margin; HAL is more cost-efficient for most tasks.
For anyone building agents for production workloads, this is the most actionable finding from GAIA. Before upgrading to a larger model, optimize your agent loop.
Level 3 Scores Expose Real Limits
Level 3 performance separates the genuinely capable systems from those that handle easy tasks well. Claude Sonnet 4.5 hits 65.39% on Level 3, more than 10 points above its nearest rival in the table. The High (extended thinking) version of the same model drops to 46.15% on Level 3 despite scoring higher on L2. Extended thinking helps with depth on medium-complexity tasks but introduces failure modes on the very longest chains.
Claude Haiku 4.5 is the Level 3 standout: 61.54% at rank 12 overall, which beats o4-mini High, Claude Opus 4 High, and every GPT entry in the table. Haiku's L3 performance at $131 per run (pricing: $1/M input tokens) makes it the best Level 3 value in the dataset by a significant margin.
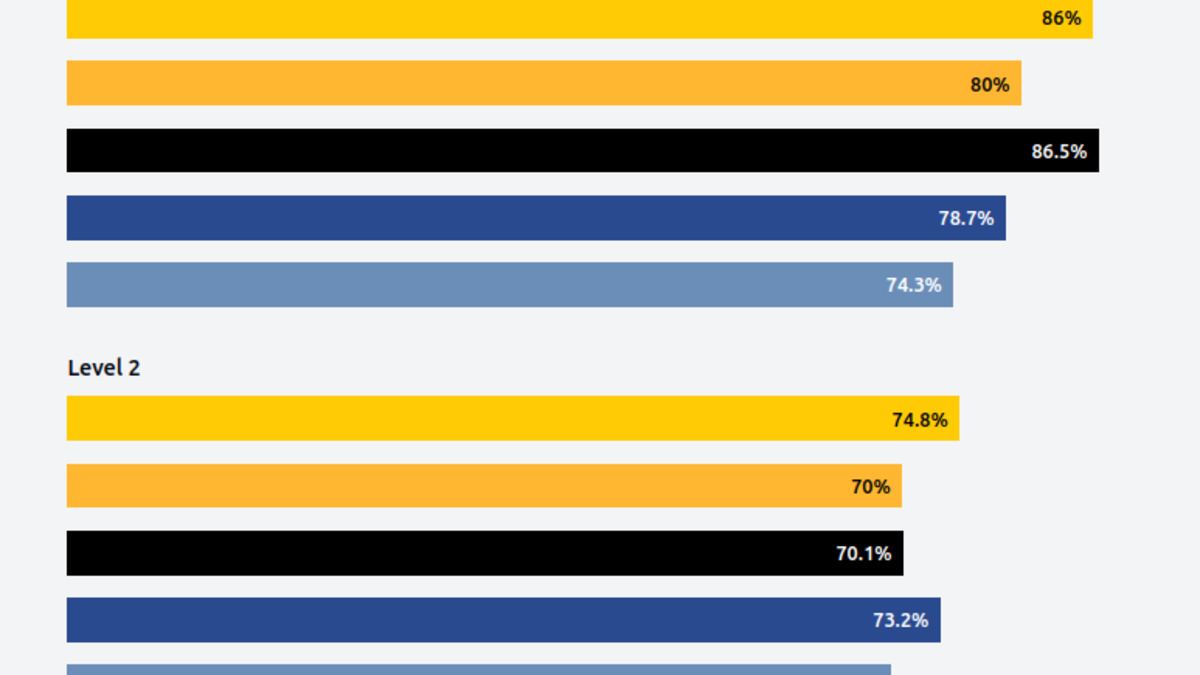 Level 3 scores cluster tightly between 47-58% across all top systems, while Level 1 shows clear separation. H2O.ai's multi-consensus approach leads at 74.8% overall.
Source: h2o.ai
Level 3 scores cluster tightly between 47-58% across all top systems, while Level 1 shows clear separation. H2O.ai's multi-consensus approach leads at 74.8% overall.
Source: h2o.ai
Cost Doesn't Scale With Accuracy
The cost column shows a pattern worth studying. Claude Opus 4 High spends $666 for 64.85%. Claude 3.7 Sonnet High spends $122 for the same 64.24%. The HF Open Deep Research framework on Claude Opus 4 costs $1,686 for 57.58% - the worst cost-efficiency entry in the entire table.
Three strongest cost-efficiency configurations:
- o4-mini High + HAL: $59 for 54.55%
- o4-mini Low + HAL: $73 for 58.18%
- Claude 3.7 Sonnet High + HAL: $122 for 64.24%
O4-mini Low sits on the Pareto frontier - no other configuration in the table offers both higher accuracy and lower cost simultaneously. For teams running frequent agentic evaluations or production tasks priced per run, $73 vs. $666 for comparable scores is a 9x cost difference that compounds over thousands of runs.
Current Frontier Models (No Framework)
HAL's evaluation covers models from mid-2025. Here's how current 2026 frontier models score on GAIA without specialized agent scaffolding - direct API calls against the public validation set (source: BenchLM.ai, May 2026):
| Rank | Model | Provider | GAIA Score |
|---|---|---|---|
| 1 | Claude Mythos Preview | Anthropic | 52.3% |
| 2 | GPT-5.4 Pro | OpenAI | 50.5% |
| 3 | GPT-5.4 | OpenAI | 48.2% |
| 4 | Claude Opus 4.6 | Anthropic | 47.8% |
| 5 | Gemini 3.1 Pro | 46.1% | |
| 6 | Claude Sonnet 4.6 | Anthropic | 45.5% |
| 7 | GPT-5.2 | OpenAI | 40.3% |
| 8 | Grok 4.1 (Grok 4 series) | xAI | 39.7% |
Direct API calls, no agentic scaffolding. Scores based on the public GAIA validation set, May 2026. GPT-5.4 Pro is a higher-compute tier of the same GPT-5.4 checkpoint.
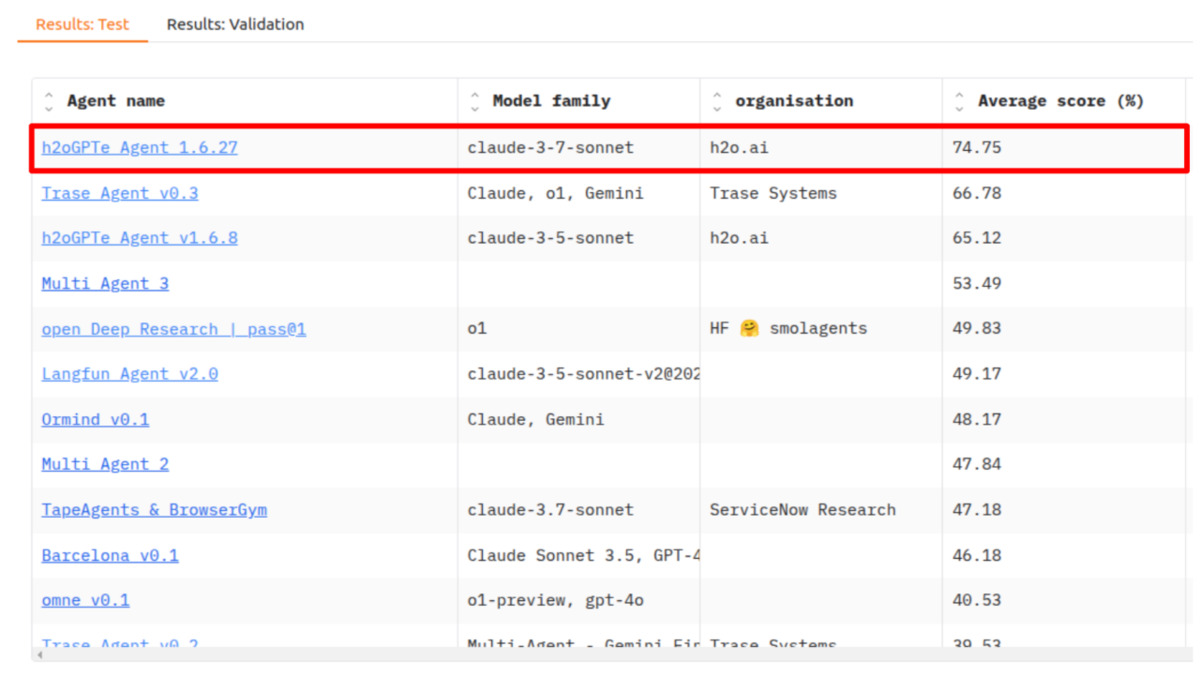 Top agentic systems reach 72-75% overall on GAIA, with Level 1 performance above 80% and Level 3 remaining the key differentiator between systems.
Source: h2o.ai
Top agentic systems reach 72-75% overall on GAIA, with Level 1 performance above 80% and Level 3 remaining the key differentiator between systems.
Source: h2o.ai
The gap between these bare scores (45-52%) and the HAL-framework scores (55-75%) confirms the scaffold effect directly. Claude Mythos Preview at 52.3% bare lands below o4-mini at 58.18% with HAL - a 2026 flagship model underperforming a 2025 budget model when the older one has proper scaffolding.
The ranking order is also worth noting: Anthropic leads bare testing as it does with HAL, but Google's Gemini 3.1 Pro at 46.1% sits above Claude Sonnet 4.6 at 45.5%, a reversal from most other benchmarks where Sonnet leads Gemini on agentic tasks.
Practical Guidance
Maximum quality: Claude Sonnet 4.5 (or current Claude Sonnet 4.6) with the open-source HAL harness from Princeton. This combination leads the Pareto frontier. The harness requires engineering work to set up, but the code is public and well-documented.
Best cost-efficiency: o4-mini in low-compute mode with HAL Generalist scaffolding. At $73 per full run versus $178 for the top Claude Sonnet configuration, it reaches 83% of the accuracy at 41% of the cost. If your agent handles thousands of tasks daily, that difference adds up.
Current model baseline (no framework setup): Claude Mythos Preview leads bare rankings at 52.3% as of May 2026. For teams building their own agent loops, this is the best starting point before framework tuning.
Budget-conscious and L3-heavy workloads: Claude Haiku 4.5 at $131 per run with HAL delivers 61.54% on Level 3 tasks - better than models costing 4-5x more. If your use case involves complex multi-step research tasks, Haiku 4.5 is worth benchmarking specifically on L3 before defaulting to flagship models.
Methodology Caveats
Validation set exposure. HAL evaluates against 165 publicly available questions with known answers. These are indexed online and likely appear in recent model training data, creating potential contamination. The 300-question private test set used for official HuggingFace leaderboard submissions is more reliable, but those results come from specialized multi-agent system submissions - not general-purpose model comparisons.
Framework dependency. Results don't transfer across agent frameworks. The same model with weaker orchestration will score 20-30 points lower. HAL's scaffolding adds retry logic, tool routing, and context management that bare API calls lack. Your production performance will land somewhere between the bare model score and the HAL score depending on how well your orchestration layer is built.
HAL's evaluation freeze. Princeton paused adding new models in early 2026. Newer models like Claude Opus 4.6, Claude Mythos Preview, and GPT-5.4 haven't been formally submitted to HAL, so there's no apples-to-apples comparison between the HAL rankings and current 2026 models with standardized scaffolding.
Scope gaps. GAIA focuses on web browsing, file handling, and multi-hop reasoning. It doesn't cover code execution agents, multi-agent coordination, or extended autonomous operation over days. Check the agentic AI benchmarks comparison and the SWE-bench coding agent leaderboard for those dimensions.
FAQ
What is the GAIA benchmark?
GAIA is a 466-question benchmark from Meta, HuggingFace, and AutoGPT that tests AI agents on real-world tasks requiring web browsing, file parsing, multi-step reasoning, and tool use. Questions have unambiguous answers across three difficulty levels. Humans score 92%; top agents reach 74-75%.
Which model scores highest on GAIA?
Claude Sonnet 4.5 with the HAL Generalist framework scores 74.55%, the highest on the standardized HAL leaderboard. Among bare models without a custom scaffold, Claude Mythos Preview leads at 52.3% as of May 2026.
How much does the agent framework affect GAIA scores?
Roughly 25-30 percentage points. The same model inside a well-built scaffold (HAL, HF Open Deep Research) scores dramatically higher than when called via direct API. This is the single largest performance lever in the GAIA data.
Are GAIA scores contaminated?
Potentially, for the public validation set. The 165 validation questions with answers are publicly available online and likely appear in recent model training data. The 300-question private test set is more reliable but accessible only through the official HuggingFace submission process.
How does GAIA compare to SWE-bench?
SWE-bench tests software engineering tasks - finding and fixing bugs in real codebases. GAIA tests general assistant tasks: web research, file parsing, multi-step reasoning. Both measure agentic capability but in different domains. Strong SWE-bench performance doesn't predict strong GAIA performance and vice versa.
What does "Pareto optimal" mean on the HAL leaderboard?
A configuration is Pareto optimal when no other tested combination has both higher accuracy and lower cost. Claude Sonnet 4.5 HAL and o4-mini Low HAL are both on the Pareto frontier - neither can be beaten on both dimensions simultaneously by any other entry in the table.
Sources:
- GAIA: a benchmark for General AI Assistants (arXiv:2311.12983) - Mialon et al., 2023
- Princeton HAL GAIA Leaderboard - top results with cost data
- HAL - About - evaluation methodology
- BenchLM.ai GAIA Benchmark 2026 - bare model scores, May 2026
- GAIA Leaderboard on HuggingFace - official submissions
- HAL harness on GitHub - open-source evaluation code
- H2O.ai tops the GAIA test - 2025 benchmark context
- GAIA: The LLM Agent Benchmark - Towards Data Science - analysis and methodology
✓ Last verified May 15, 2026
