Cost Efficiency Leaderboard: Best AI Performance Per Dollar
Rankings of AI models by cost efficiency in May 2026, comparing performance per dollar across frontier and budget models. Updated with DeepSeek V4, GPT-5.5, and Kimi K2.6.

Two and a half years ago, GPT-4 cost $30 per million input tokens and was the only serious option for hard tasks. Today, DeepSeek V3.2 delivers 82.4% on GPQA Diamond for $0.28 per million tokens. In April 2026 alone, three new models rewrote the efficiency map: DeepSeek V4 Flash arrived at half the price of V3.2 with stronger benchmarks, Kimi K2.6 pushed coding performance past 80% SWE-bench at under a dollar per million, and GPT-5.5 raised the absolute capability ceiling while doubling the price. The gap between budget and frontier is closing from both ends.
This leaderboard ranks models not by raw capability but by what you actually get per dollar. The best model for your use case isn't the one that tops every benchmark - it's the one that tops the benchmark that matters for your workload at a price that makes the project viable.
TL;DR
- DeepSeek V3.2 holds the top confirmed efficiency score: 82.4% GPQA Diamond at $0.28/M input - 17x cheaper than Gemini 3.1 Pro for 87% of its benchmark performance
- DeepSeek V4 Flash is the May 2026 dark horse: $0.14/M input with stronger benchmarks than V3.2, but Arena Elo still accumulating - watch this closely
- For frontier-tier performance with the best price-to-benchmark ratio, Gemini 3.1 Pro at $2.00/M input and 94.3% GPQA leads all models with published Arena Elo above 1490
Benchmark Methodology
The Efficiency Score in this leaderboard is a composite of two confirmed metrics divided by input price: GPQA Diamond percentage (from the GPQA Diamond benchmark, measuring graduate-level scientific reasoning) multiplied by Arena Elo (from lm.arena.ai, reflecting blind human preference across millions of comparisons), divided by input price per million tokens, then normalized so the top scorer equals 100.
This formula rewards models that score high on both reasoning accuracy and human preference, while penalizing high prices. Models released fewer than 30 days before publication often lack enough Arena votes for a stable Elo rating - those are marked "Early" and discussed in the analysis rather than assigned a composite score.
GPQA Diamond and Arena Elo scores used here come from the April 2026 overall rankings published on this site, and from provider announcements and independent evaluators. Pricing reflects standard, non-cached API rates as of May 1, 2026.
Cost Efficiency Rankings
| Rank | Model | Provider | Input / Output (per 1M tokens) | GPQA Diamond | Arena Elo | Efficiency Score |
|---|---|---|---|---|---|---|
| 1 | DeepSeek V3.2 | DeepSeek | $0.28 / $0.42 | 82.4% | ~1361 | 100.0 |
| 2 | Mistral Large 3 | Mistral AI | $0.50 / $1.50 | 43.9% | ~1418 | 31.1 |
| 3 | Gemini 3.1 Pro | $2.00 / $12.00 | 94.3% | ~1500 | 17.7 | |
| 4 | Grok 4.20 | xAI | $2.00 / $6.00 | ~88%* | ~1493 | 16.4 |
| 5 | GPT-5.4 | OpenAI | $2.50 / $15.00 | 92.8% | ~1484 | 13.8 |
| 6 | Grok 4 | xAI | $3.00 / $15.00 | 88.4% | ~1375 | 10.1 |
| 7 | Claude Sonnet 4.6 | Anthropic | $3.00 / $15.00 | 74.1% | ~1438 | 8.9 |
| 8 | Claude Opus 4.7 | Anthropic | $5.00 / $25.00 | TBD | TBD | TBD |
| 9 | GPT-5.5 | OpenAI | $5.00 / $30.00 | TBD | Early | TBD |
| 10 | GPT-5.2 Pro | OpenAI | $10.00 / $30.00 | 93.2% | ~1402 | 3.3 |
Grok 4.20 GPQA score is an estimate based on the earlier Grok 4 family. xAI hasn't published official GPQA Diamond results for this model. TBD = benchmark not yet published at time of writing. Early = fewer than 30 days on the Arena, Elo not yet stable.
Efficiency Score = (GPQA% x Arena Elo) / Input Price, normalized to 100 for the top scorer. Models marked TBD or Early are discussed in the Key Takeaways section below.
Open-Weight and Self-Hosted Options
These models are free to self-host. Infrastructure cost depends on your GPU setup - rough amortized estimates assume H100 access at current cloud rates with moderate utilization.
| Model | License | GPQA Diamond | Arena Elo | Est. Self-Host Cost/1M |
|---|---|---|---|---|
| Gemma 4 31B | Apache 2.0 | 84.3% | ~1452 | ~$0.20 |
| Qwen 3.6-35B-A3B | Apache 2.0 | 86.0% | TBD | ~$0.18 |
| Llama 4 Maverick | Llama License | 69.8% | ~1320 | ~$0.25 |
At $0.18-$0.25 estimated self-host cost, these open-weight models land in the same cost tier as DeepSeek V3.2 on the API - but with full data privacy, no rate limits, and the option to fine-tune.
 Artificial Analysis Intelligence Index (v4.0) as of May 2026. GPT-5.5 and Grok 4 variants lead intelligence rankings; the speed chart shows smaller models like IBM Granite and Mistral 3.3B running at 200+ tokens/second.
Source: artificialanalysis.ai
Artificial Analysis Intelligence Index (v4.0) as of May 2026. GPT-5.5 and Grok 4 variants lead intelligence rankings; the speed chart shows smaller models like IBM Granite and Mistral 3.3B running at 200+ tokens/second.
Source: artificialanalysis.ai
Key Takeaways
DeepSeek V3.2 Is Still the API Value Champion
Nothing on the board has displaced DeepSeek V3.2 as the most efficient paid API option among models with stable, published benchmarks. At $0.28 per million input tokens and $0.42 output, it scores 82.4% on GPQA Diamond and 73.1% on SWE-bench Verified. That puts it within 12 percentage points of Gemini 3.1 Pro on GPQA, at one-seventh the input cost.
For applications that can tolerate performance slightly below the absolute frontier - which describes most production workloads - V3.2 remains the default starting point. It's also open-weight, meaning if your volumes grow large enough to justify self-hosting, you can run it locally and remove API costs completely.
DeepSeek V4 Flash Is the One to Watch
DeepSeek V4, released April 24, 2026, arrives in two variants. V4 Flash costs $0.14 per million input tokens - half what V3.2 charges - and early BenchLM data shows it outperforming V3.2 across general knowledge tasks. V4 Pro costs $1.74 per million input tokens (post-launch promo period), with SWE-bench Verified scores comparable to Gemini 3.1 Pro's 80.6%.
V4 Flash doesn't yet have a stable Arena Elo - it launched April 24, fewer than ten days before this update - so we can't include it in the efficiency ranking table yet. Once Arena data builds up, expect it to land at or above V3.2's top position. If early benchmarks hold, V4 Flash may be the most efficient paid API model in history.
DeepSeek V4 Flash at $0.14/M input: if early benchmarks hold, it's headed for the top of this table.
The Emerging Frontier: Kimi K2.6 and GPT-5.5
Two other April 2026 arrivals are reshaping the upper end of the cost conversation.
Kimi K2.6, from Moonshot AI, costs $0.95 per million input tokens and scores 54 on the Artificial Analysis Intelligence Index - placing it above GPT-5.2 in raw capability per independent evaluation. Its coding benchmarks are especially strong, with BenchLM ranking it #12 overall and #7 specifically on coding tasks. At $0.95/M, it undercuts Claude Sonnet 4.6 ($3.00/M), Grok 4 ($3.00/M), and GPT-5.4 ($2.50/M) while matching or topping several of them on coding-specific benchmarks. Once Arena Elo stabilizes, it could slot into the top 5 of this table.
GPT-5.5, released April 23, 2026 at $5.00 per million input tokens and $30.00 output, is OpenAI's most capable model yet - Terminal-Bench 2.0 score of 82.7%, seven points above GPT-5.4. The problem is the price. At double GPT-5.4's input cost, it needs to deliver substantially better results on your specific task to justify the premium. For agentic coding and long-horizon computer use (OSWorld-Verified 78.7%), it may be worth it. For most text-heavy workloads, GPT-5.4 or Gemini 3.1 Pro at half the price will be good enough.
The Frontier Is No Longer Winner-Takes-All
Until recently, frontier performance meant paying frontier prices. That held from early 2024 through mid-2025. Now the gap between "good enough" and "best" has collapsed to the point where the right question isn't "can I afford the best?" but "does my workload justify it at all?"
Consider: Gemma 4 31B is free under Apache 2.0, scores 84.3% on GPQA Diamond, and has an Arena Elo of ~1452. That's above Claude Sonnet 4.6 in human preference, at essentially zero marginal cost. Qwen 3.6-35B-A3B scores 86.0% on GPQA Diamond under Apache 2.0. The open-weight tier has caught the proprietary middle class.
Feb 2024 - GPT-4 at $30/M input is the benchmark. No serious alternative exists for hard reasoning tasks.
Jan 2025 - DeepSeek V3 arrives at $0.27/M input. GPT-4-level performance drops by 99%.
Apr 2026 - DeepSeek V4 Flash launches at $0.14/M input. The "good enough for production" tier now costs less than a cup of coffee per billion tokens.
Mistral Large 3 Is Underrated
Mistral Large 3 ranks #2 on efficiency despite a 43.9% GPQA Diamond score that looks unimpressive compared to frontier models. That number is misleading taken in isolation. At $0.50 per million input tokens, Mistral Large 3 scores 1418 on Arena Elo - meaning users prefer its outputs over most competitors in the $1-3 per million range. For tasks where human preference matters more than scientific reasoning accuracy (creative writing, customer service, summarization, copyediting), Mistral Large 3 offers strong value that the GPQA number doesn't fully capture.
Practical Guidance
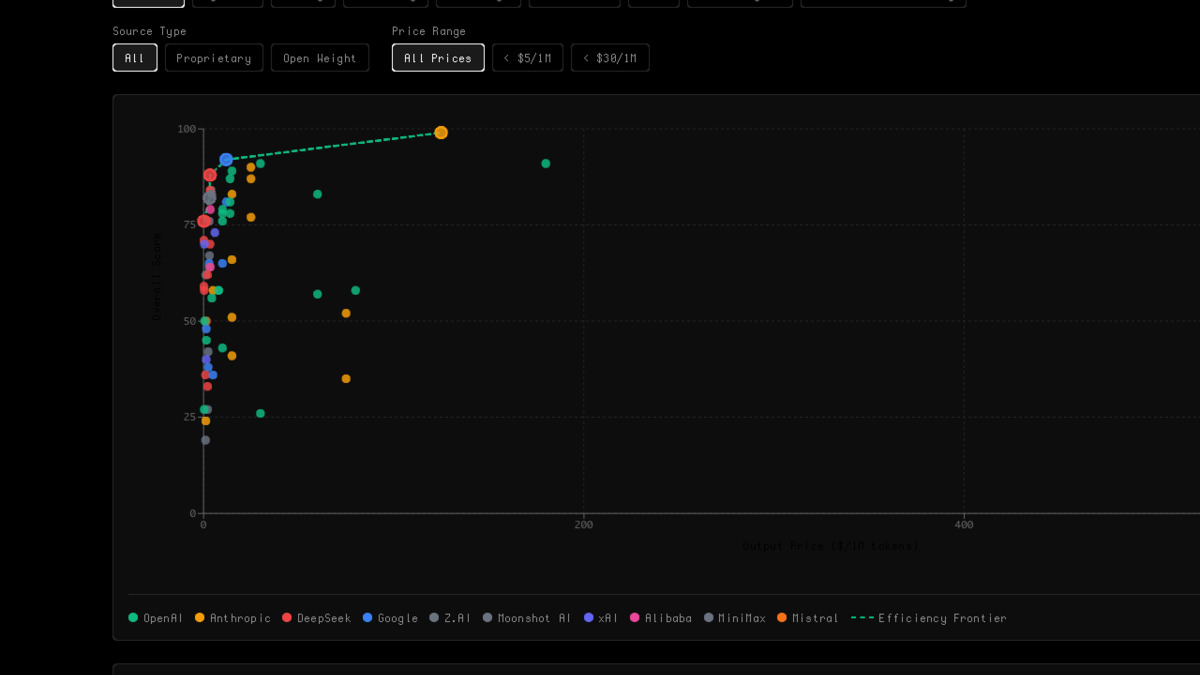 BenchLM's LLM Price vs Performance chart plots benchmark score against output token price. Models on the efficiency frontier (dashed line) offer the best value at each price point. DeepSeek V4 Flash sits furthest along the frontier.
Source: benchlm.ai
BenchLM's LLM Price vs Performance chart plots benchmark score against output token price. Models on the efficiency frontier (dashed line) offer the best value at each price point. DeepSeek V4 Flash sits furthest along the frontier.
Source: benchlm.ai
For startups and prototypes: Start with DeepSeek V3.2 or DeepSeek V4 Flash via API. V3.2 is battle-tested and well-documented; V4 Flash is newer and cheaper - both are under $0.50/M. Once you know your volume, reassess whether self-hosting a Gemma 4 31B or Qwen 3.6-35B-A3B makes more financial sense.
For coding-heavy workloads: Kimi K2.6 at $0.95/M or DeepSeek V4 Pro at $1.74/M are the May 2026 picks. Both substantially undercut Claude Sonnet 4.6 and GPT-5.4 while posting comparable or better SWE-bench scores. See our review of DeepSeek V4 Pro for hands-on testing.
For agentic and long-horizon tasks: Grok 4.20 at $2.00/M input and 2M token context leads on agentic speed (234.9 tokens/second) and offers the largest context window of any frontier API model at a reasonable price. Gemini 3.1 Pro is the alternative if raw reasoning accuracy matters more than speed.
For quality-critical applications: Gemini 3.1 Pro at $2.00/M input is the best price-to-frontier ratio: highest GPQA Diamond (94.3%) and highest Arena Elo (~1500) of any model with a public benchmark track record. If you need the absolute ceiling and cost is secondary, GPT-5.5 or Claude Opus 4.7 - though neither has published standard benchmarks at time of writing.
For high-volume self-hosting: Gemma 4 31B runs on two RTX 4090s or a single H100. At current cloud GPU rates, self-hosting at moderate use costs roughly $0.20 per million tokens - in the same range as DeepSeek V3.2 API, with the added benefits of no rate limits, full data privacy, and a model you can fine-tune. For a detailed comparison of self-hosting versus API costs, the break-even at mid-volume (1B+ tokens/month) currently favors self-hosting.
FAQ
What is the most cost-efficient AI model right now?
DeepSeek V3.2 holds the highest confirmed efficiency score among models with stable benchmarks: 82.4% GPQA Diamond and Arena Elo ~1361 at $0.28/M input. DeepSeek V4 Flash ($0.14/M) looks stronger on early data but lacks a stable Arena Elo.
Which model offers the best price-to-reasoning-accuracy ratio?
Gemini 3.1 Pro at $2.00/M input with 94.3% GPQA Diamond. Nothing cheaper has published a higher GPQA score with a verified Arena Elo above 1490.
When does self-hosting beat API pricing?
Roughly at 1 billion tokens per month or more, assuming you have engineering capacity to operate the infrastructure. Below 100M tokens/month, API convenience usually wins. See our full self-hosting cost guide.
How often do cost efficiency rankings change?
Frequently. In April 2026 alone, three new models (DeepSeek V4, Kimi K2.6, GPT-5.5) changed the picture. Pricing also shifts - DeepSeek V4 Pro ran a 75% launch discount through May 5. We update this table monthly.
Is Mistral Large 3 really better value than GPT-5.4?
On pure cost efficiency math, yes. Mistral Large 3's GPQA score is much lower, but its Arena Elo of ~1418 at $0.50/M input means users prefer its outputs over most mid-range models. For tasks where human preference predicts output quality better than academic benchmarks - which is most commercial applications - Mistral Large 3 is under-priced relative to its actual utility.
Does the Efficiency Score account for output token costs?
No - the table uses input price for comparability, since input/output ratios vary by workload. For output-heavy workloads (long responses, code generation), recalculate using a blended 3:1 input-to-output ratio. On a blended basis, Grok 4.20 ($2.00/$6.00) improves significantly versus Gemini 3.1 Pro ($2.00/$12.00).
Sources:
- Artificial Analysis - LLM Leaderboard
- LM Arena Chatbot Arena Leaderboard
- DeepSeek API Pricing
- Anthropic Claude Pricing
- Google Gemini API Pricing
- xAI Grok API Docs
- OpenAI - Introducing GPT-5.5
- BenchLM - LLM Price Performance
- Kimi K2.6 Tech Blog
- DeepSeek V4 Pro on OpenRouter
- LLM API Pricing Comparison 2026
- Self-Hosting Cost Analysis 2026
✓ Last verified May 1, 2026
