Audio Understanding Benchmarks Leaderboard 2026
Rankings of the best audio language models on MMAU, MMAU-Pro, and other benchmarks covering speech reasoning, music understanding, and environmental sound identification.

Audio understanding is the capability that most AI benchmark trackers still underserve. The typical multimodal leaderboard tracks vision: image captioning, chart reading, visual question answering. But a model that aces visual benchmarks can be surprisingly weak when asked to identify a chord progression, reason about environmental noise, or follow the thread of a spoken conversation. These are different skills built on different architectures, and the results don't transfer cleanly from one domain to the other.
This leaderboard focuses specifically on understanding audio - not creating it. TTS and STT performance lives in our AI Voice and Speech Leaderboard; the benchmarks here measure whether a model can reason about what it hears, not just transcribe it. That distinction matters. A model can achieve 3% word error rate on LibriSpeech while scoring below 40% on MMAU-Pro's reasoning tasks, because understanding requires more than clean transcription.
TL;DR
- Gemini 2.5 Flash leads MMAU-Pro at 59.2% - still 18 points below the 77.9% human baseline
- Step-Audio-R1 tops the original MMAU leaderboard at 77.7%, but uses an agentic chain-of-thought approach that inflates comparisons with standard single-pass models
- Qwen2.5-Omni-7B is the best open-weight model on MMAU (65.6%) and holds second on MMAU-Pro (52.2%)
- Multi-audio reasoning and spatial audio remain unsolved: no model clears 30% on those subtasks
The Benchmark Overview
Four benchmarks dominate current audio understanding evaluation. They measure overlapping but distinct capabilities, so a strong overall picture requires looking at more than one.
MMAU (Massive Multi-task Audio Understanding) is the most widely cited general benchmark. It contains 10,000 audio clips with human-annotated question-answer pairs across speech, environmental sound, and music. Questions fall into two types: information retrieval (does the audio contain a certain sound?) and reasoning (what emotional state does the speaker convey, and why?). The benchmark uses multiple-choice format across 27 task categories. As of January 2026, evaluation runs through a dedicated Hugging Face Space after the original EvalAI setup was retired.
MMAU-Pro was released in August 2025 and represents a harder, more realistic test. It contains 5,305 expert-annotated instances and evaluates 49 distinct auditory skills, including categories not present in the original: spatial audio reasoning, multi-audio understanding (questions spanning two or more audio clips), open-ended QA, and instruction following. The human baseline on MMAU-Pro sits at 77.9%, and no current model beats 60%.
AIR-Bench (Audio Instruction Response Benchmark) takes a different approach. Rather than multiple-choice questions, it uses a LLM judge to assess model responses to open-ended audio instructions. It covers 19 task types with roughly 19,000 single-choice items plus 2,000 open-ended instances. The benchmark is useful for measuring conversational audio understanding rather than discrete classification accuracy.
Dynamic-SUPERB Phase-2 is the largest in scope: 180 tasks spanning speech, music, and general sound, now supported by the ICLR 2025 version of the benchmark. It includes classification, regression, and sequence-generation formats. It's more comprehensive than MMAU but harder to summarize in a single number, which limits how often it shows up in direct comparisons.
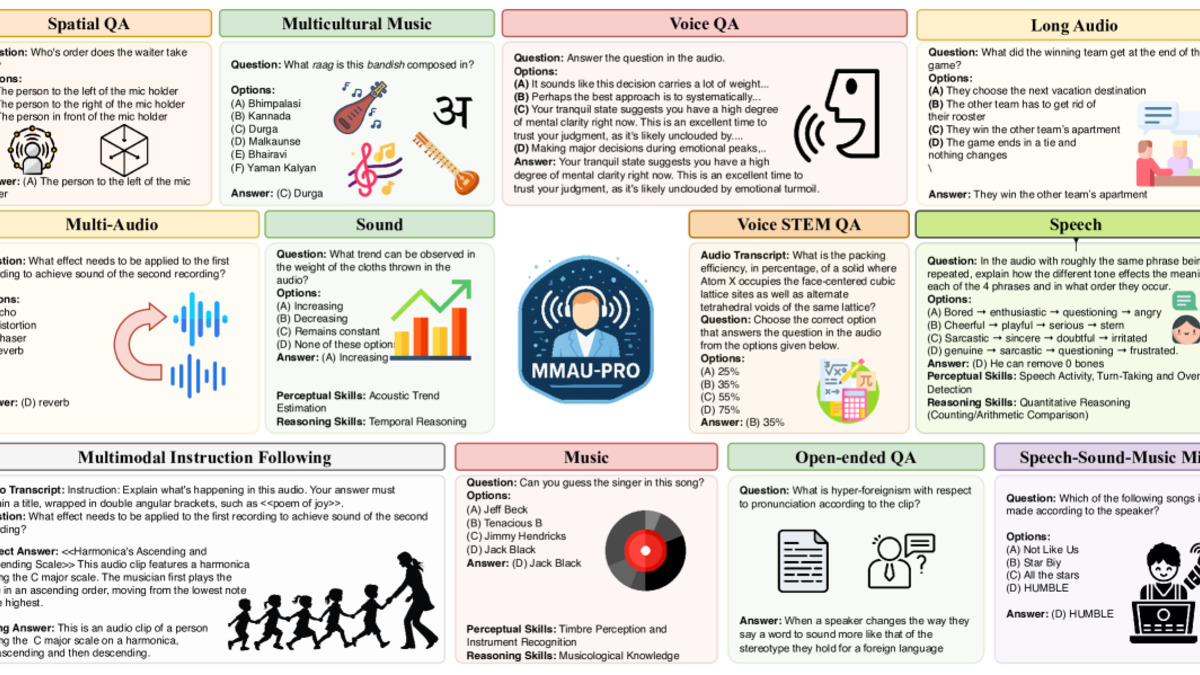 MMAU-Pro assesses models across 7 dimensions: Sound, Music, Speech, Spatial, Voice, Multi-Audio, and Open-Ended QA. Most models struggle with the last two.
Source: arxiv.org
MMAU-Pro assesses models across 7 dimensions: Sound, Music, Speech, Spatial, Voice, Multi-Audio, and Open-Ended QA. Most models struggle with the last two.
Source: arxiv.org
Rankings - MMAU (Original)
The original MMAU benchmark uses a test-mini split (1,000 items) and a full test split (9,000 items). The scores below are from the test-mini split unless otherwise noted, which is the most widely reported figure.
| Rank | Model | Provider | Sound | Music | Speech | Avg |
|---|---|---|---|---|---|---|
| 1 | Step-Audio-R1 | StepFun | - | - | - | 77.7% |
| 2 | Gemini 2.5 Pro | - | - | - | 77.4% | |
| 3 | Audio Flamingo 3 | NVIDIA | - | - | - | 72.4% |
| 4 | Kimi-Audio | Moonshot AI | 73.3% | 61.7% | 60.7% | ~65.2% |
| 5 | Qwen2.5-Omni-7B | Alibaba | 67.9% | 69.2% | 59.8% | 65.6% |
| 6 | Gemini 2.0 Flash | - | - | - | 59.9% | |
| 7 | Qwen2.5-Omni-3B | Alibaba | 70.3% | 60.5% | 59.2% | 63.3% |
| 8 | Audio Flamingo 2 | NVIDIA | 65.1% | 72.9% | - | ~69.0% |
| 9 | GPT-4o Audio | OpenAI | - | - | - | ~64.9% |
| 10 | Gemini Pro v1.5 | - | - | - | 54.9% | |
| 11 | Qwen2-Audio | Alibaba | - | - | - | 52.5% |
Notes on Step-Audio-R1: The 77.7% figure comes from StepFun's November 2025 technical report and uses an extended chain-of-thought reasoning setup where the model generates reasoning traces before answering. This is more analogous to an o1-style inference approach than a standard single-pass forward pass. Comparing it directly to models evaluated without chain-of-thought is apples-to-oranges. When reasoning is disabled, performance drops substantially.
On Gemini 2.5 Pro: The 77.4% score appears in the MMAU-Pro paper as a reference point for the original MMAU benchmark, not MMAU-Pro. Gemini 2.5 Pro's audio capabilities are native to the model rather than a specialized audio encoder, which shows in some categories and hurts in others.
Rankings - MMAU-Pro
MMAU-Pro is the harder test and the one that better separates genuine audio intelligence from pattern matching on constrained multiple-choice sets.
| Rank | Model | Provider | Sound | Music | Speech | Spatial | Multi-Audio | Avg |
|---|---|---|---|---|---|---|---|---|
| 1 | Gemini 2.5 Flash | 51.9% | 64.9% | 73.4% | 36.3% | 21.2% | 59.2% | |
| 2 | Gemini 2.0 Flash | 48.4% | 56.9% | 69.5% | 34.6% | 26.5% | 55.7% | |
| 3 | GPT-4o Audio | OpenAI | - | - | - | - | - | 52.5% |
| 4 | Qwen2.5-Omni-7B | Alibaba | 47.6% | 61.5% | 57.4% | 41.2% | 24.3% | 52.2% |
| 5 | Audio Flamingo 3 | NVIDIA | 55.9% | 61.7% | 58.8% | 26.8% | 26.0% | 51.7% |
| 6 | GPT-4o-mini Audio | OpenAI | - | - | - | - | - | 48.3% |
| 7 | Ming-Lite-Omni-1.5 | - | - | - | - | - | - | 47.4% |
| 8 | Kimi-Audio | Moonshot AI | - | - | - | - | - | 46.6% |
| 9 | Qwen2.5-Omni-3B | Alibaba | - | - | - | - | - | 46.1% |
| 10 | SALMONN-13B | ByteDance | - | - | - | - | - | 39.6% |
| 11 | SALMONN-7B | ByteDance | - | - | - | - | - | 34.5% |
| H | Human | - | - | - | - | - | - | 77.9% |
Source: MMAU-Pro paper (arXiv 2508.13992), August 2025. Cells marked - weren't individually broken out in the reported results.
 Model performance on MMAU-Pro's seven evaluation dimensions. The Multi-Audio column shows where every model struggles - no system currently exceeds 30%.
Source: arxiv.org
Model performance on MMAU-Pro's seven evaluation dimensions. The Multi-Audio column shows where every model struggles - no system currently exceeds 30%.
Source: arxiv.org
Key Takeaways
Gemini Leads but the Gap to Humans Is Large
Gemini 2.5 Flash at 59.2% on MMAU-Pro is the top result from a standard single-pass evaluation. That sounds impressive until you look at the human baseline of 77.9%. The 18.7-point gap isn't minor. It represents tasks that humans find straightforward but models consistently fumble: understanding audio context from multiple clips, reasoning about spatial sound placement, and creating open-ended explanations rather than selecting from a list.
Google's two-model lead (2.5 Flash ahead of 2.0 Flash at 55.7%) is consistent with the pattern seen in our multimodal benchmarks leaderboard: iterative Gemini releases improve audio capabilities in ways that aren't always visible from text-only benchmarks.
Open-Weight Models Are Competitive in Some Lanes
Qwen2.5-Omni-7B at 52.2% on MMAU-Pro sits within 7 points of GPT-4o Audio (52.5%). That's a 7-billion-parameter open-weight model matching a closed frontier system on a hard reasoning benchmark. The Alibaba/Qwen team has made audio a first-class modality rather than an add-on - Alibaba's open-source push with Qwen has been consistent here.
Audio Flamingo 3 from NVIDIA (51.7%) shows what a dedicated audio research lab can accomplish with a purpose-built model. On the original MMAU, Audio Flamingo 3 reaches 72.4%, which puts it ahead of Qwen2.5-Omni on that benchmark despite being behind on MMAU-Pro. The gap suggests AF3 is tuned well for single-domain audio tasks but struggles with MMAU-Pro's novel subtasks (spatial reasoning, multi-audio).
Music Understanding Splits the Field
Music is the domain that most clearly separates specialist models from generalists. On MMAU-Pro, Gemini 2.5 Flash scores 64.9% on music while scoring only 51.9% on environmental sound. Qwen2.5-Omni shows almost the inverse: 61.5% on music but 47.6% on sound. NVIDIA's Audio Flamingo 2 reached 72.9% on MMAU Music in the original benchmark - the highest music-domain score in published results - attributable to the custom AF-CLAP audio encoder that was specifically trained on music data.
Models that are primarily speech-trained tend to underperform on music reasoning. Understanding chord progressions, identifying genre from timbre, or recognizing emotional arc in a composition requires training data and encoding choices that general-purpose multimodal models often skip.
Multi-Audio Reasoning Is Unsolved
The Multi-Audio column is damning for every system on MMAU-Pro. The best result is GPT-4o Audio at 26.5% on tasks involving two or more audio clips. Gemini 2.5 Flash scores 21.2%. To put that in context: random chance on a 4-option multiple-choice question gives you 25%. Most models are barely above random on multi-audio tasks.
This matters because real-world audio understanding rarely involves a single clean clip. A user asking about a conversation might be working with overlapping voices, background noise, or two separate recordings. The current benchmark results suggest no production system handles this reliably.
The Agentic Approach Jumps to the Front
AudioToolAgent (arXiv 2510.02995, February 2026) reaches 77.5% on the original MMAU by coordinating multiple specialized audio models through a central LLM. A coordinator model decides which specialized tool to call - ASR for speech content, a music analysis model for melody questions, an environmental sound classifier for acoustic events - and arbitrates between conflicting outputs. The 77.5% figure matches human performance on MMAU and is a genuine result, not inflated by dataset contamination.
The relevant question is whether this architecture counts as "audio understanding" or "audio tool use." The model doesn't directly perceive audio; it coordinates systems that do. For practitioners building real systems, the distinction may not matter. For anyone trying to measure whether a single model understands audio, it's an important caveat. The rise of agentic audio approaches rhymes with what we've seen in agentic AI benchmarks more broadly - the agentic wrapper often outperforms the base model by large margins.
Domain Breakdowns
Speech Reasoning
Speech reasoning goes beyond ASR. These tasks ask models to identify the speaker's emotional state, reason about word emphasis and phonemic stress, follow argument structure across a dialogue, and answer factual questions grounded in spoken content.
Gemini 2.5 Flash leads on MMAU-Pro speech tasks at 73.4%, with Gemini 2.0 Flash close behind at 69.5%. The speech gap between Google's models and the open-weight competition is wider here than in other domains - 57.4% for Qwen2.5-Omni-7B versus 73.4% for Gemini 2.5 Flash is a 16-point spread.
Phi-4-Multimodal from Microsoft (arXiv 2503.01743) doesn't appear in the MMAU-Pro table but scores well on speech-specific tasks: it leads the Hugging Face Open ASR Leaderboard with a 6.14% word error rate and performs on par with GPT-4o on FLEURS speech translation. Phi-4-Multimodal's speech understanding is strong; its music and environmental sound scores are not published in standardized benchmark format.
Recent work from IBM - IBM Granite 4 Speech - focuses on edge ASR rather than full audio reasoning, so it doesn't appear in MMAU rankings but is worth tracking for latency-constrained deployment.
Music Understanding
Music tasks require knowledge of theory (intervals, chords, scales), genre familiarity, and the ability to reason about emotional content in tonal material. MuchoMusic is a specialized music reasoning benchmark where Audio Flamingo 2 scored 56.5% against 51.4% for the prior state of the art.
The GTZAN zero-shot genre classification task (69.1% for Audio Flamingo 2) and ESC50 environmental sound classification (83.9%) give a cleaner read on classification-level capabilities separate from open-ended reasoning.
Environmental Sound Identification
Environmental sound tasks cover acoustic event detection and scene classification: identifying a dog barking, distinguishing rain from running water, recognizing a passing truck. Kimi-Audio leads published results on MMAU sound tasks at 73.3%, ahead of Qwen2.5-Omni-7B at 67.9% and Gemini 2.0 Flash's 48.4% on MMAU-Pro (though this is a harder variant).
CochlScene is a scene-classification benchmark; ClothoAQA tests audio question answering on environmental clips. Audio Flamingo 2 reached 86.9% on ClothoAQA unannotated, which is the highest published result on that benchmark.
Practical Guidance
For speech reasoning tasks in production: Gemini 2.5 Flash's 73.4% on MMAU-Pro speech is the strongest single-model result at this time. If you're building a system that needs to reason about spoken content - transcripts with emotional analysis, meeting summarization that captures speaker intent, dialogue quality assessment - Gemini 2.5 Flash is the production choice. The API is available and the audio modality is native to the model.
For open-weight deployments: Qwen2.5-Omni-7B at 65.6% on MMAU and 52.2% on MMAU-Pro is the strongest open-weight option for audio understanding. It's available through Hugging Face and runs on a single high-end consumer GPU. For teams that can't use closed APIs due to data privacy constraints, this is the starting point. For local inference options, llama.cpp recently landed three audio models including Qwen3-Omni that can run on consumer hardware.
For music-heavy applications: Audio Flamingo 3 from NVIDIA is purpose-built for audio and beats generalist models on music tasks. The model is open-sourced. If your use case is music analysis, genre classification, or music theory questions, AF3 is worth assessing before defaulting to a larger generalist.
For multi-audio tasks: No current model solves multi-audio reasoning reliably. If you have tasks involving multiple audio sources or need models to compare two recordings, the current benchmarks suggest you should expect low accuracy and design your system with human-in-the-loop fallbacks for the cases that matter.
Budget option: Qwen2.5-Omni-3B scores 63.3% on MMAU - only 2 points behind the 7B variant - with substantially lower compute requirements. For cost-sensitive deployments where you don't need the top of the frontier, the 3B variant is competitive.
FAQ
What is the hardest audio understanding benchmark?
MMAU-Pro (5,305 instances, 49 auditory skills) is currently the most challenging, with a human baseline of 77.9% and the top model at 59.2%. Multi-audio reasoning and spatial reasoning subtasks have no model above 30%.
Which model leads audio understanding benchmarks?
Gemini 2.5 Flash leads MMAU-Pro at 59.2%. Step-Audio-R1 hits 77.7% on the original MMAU but uses extended chain-of-thought reasoning, making direct comparisons with standard models misleading.
How does MMAU differ from MMAU-Pro?
MMAU has 10,000 items across speech, sound, and music using multiple-choice questions. MMAU-Pro has 5,305 expert-annotated items and adds new categories - spatial audio, multi-audio reasoning, and open-ended QA - that are harder to game with pattern matching.
Is audio understanding different from speech recognition?
Yes. Speech recognition (ASR) measures transcription accuracy. Audio understanding measures whether a model can reason about audio content: emotional state, musical structure, acoustic context. A model can excel at ASR while failing at understanding tasks.
Can open-source models compete with GPT-4o on audio tasks?
On MMAU-Pro, Qwen2.5-Omni-7B (52.2%) is within 0.3 points of GPT-4o Audio (52.5%). Open-weight models are competitive. On the original MMAU, open-weight models have surpassed GPT-4o in several published comparisons.
Sources
- MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
- MMAU official leaderboard
- MMAU-Pro: A Challenging and Comprehensive Benchmark for Holistic Evaluation of Audio General Intelligence
- Audio Flamingo 2 paper (arXiv 2503.03983)
- Audio Flamingo 3 - NVIDIA Research
- Qwen2.5-Omni technical report
- Qwen2.5-Omni GitHub README with benchmark scores
- Kimi-Audio technical report (arXiv 2504.18425)
- Kimi-Audio evaluation leaderboard
- Step-Audio-R1 technical report (arXiv 2511.15848)
- AudioToolAgent (arXiv 2510.02995)
- Phi-4-Mini technical report (arXiv 2503.01743)
- Dynamic-SUPERB Phase-2 at ICLR 2025
- AIR-Bench: Benchmarking Large Audio-Language Models (arXiv 2402.07729)
✓ Last verified April 19, 2026
