Google TPU 8t - AI Training at ExaFLOP Scale
Google's TPU 8t packs 12.6 FP4 PFLOPs and 216GB HBM3e per chip, scaling to 9,600-chip superpods with 121 ExaFLOPS and 2 petabytes of shared HBM for massive model training.

TL;DR
- Google's eighth-generation training chip: 12.6 FP4 PFLOPs and 216GB HBM3e per chip
- Scales to a 9,600-chip superpod with 121 FP4 ExaFLOPS and 2 petabytes of shared HBM
- 2.7x better training price-performance versus TPU v7 Ironwood
- Training-only chip - Google separated training and inference for the first time this generation
Overview
Google's TPU 8t is the training half of the company's eighth-generation TPU family, announced at Google Cloud Next on April 22, 2026. For the first time in the decade-long TPU program, Google shipped two distinct chips for two distinct jobs: the 8t for training and the TPU 8i for inference. The split is a significant architectural decision, trading the flexibility of a general-purpose accelerator for per-workload optimization.
The 8t delivers 12.6 FP4 petaFLOPS per chip with 216GB of HBM3e running at 6,528 GB/s, built on TSMC's N3 process. That per-chip bandwidth is lower than the AMD MI455X or NVIDIA Vera Rubin NVL144, but the TPU 8t isn't designed to win that race. It's designed to scale - to 9,600 chips in a single superpod with a petabyte-scale shared memory pool and a datacenter-spanning network fabric called Virgo that holds the whole thing together.
At superpod scale, the 8t system delivers 121 FP4 ExaFLOPS of compute from 2 petabytes of shared HBM across 9,600 chips. Google's Virgo network fabric links those chips with up to 47 petabits per second of non-blocking bi-sectional bandwidth, and the architecture extends further - up to one million TPU 8t chips can be connected into a single logical training cluster across multiple data centers. That's the scale at which Google trains its largest Gemini 3 class models.
Key Specifications
| Specification | Details |
|---|---|
| Manufacturer | |
| Product Family | 8th Generation TPU |
| Chip Type | TPU (ASIC) |
| Process Node | TSMC N3 |
| Memory | 216GB HBM3e |
| Memory Bandwidth | 6,528 GB/s |
| FP4 Performance | 12.6 PFLOPs per chip |
| FP8 Performance | Not disclosed |
| On-Chip SRAM | 128 MB |
| TDP | Not disclosed |
| Inter-Chip Interconnect (ICI) | 2x vs previous gen (ICI bandwidth not specified) |
| Network Fabric | Virgo (up to 47 Pb/s non-blocking bi-sectional BW) |
| Superpod Scale | 9,600 chips, 2 PB shared HBM, 121 FP4 ExaFLOPS |
| Max Cluster Scale | 1 million chips (multi-datacenter) |
| Release Date | 2026-H2 |
Performance Benchmarks
The most honest comparison for the TPU 8t is against its predecessor and against the system-level economics Google reports, not a per-chip TFLOPS race. Per-chip TFLOPS numbers without their networking context mislead more than they inform.
| Metric | Google TPU 8t | Google TPU v7 Ironwood | AMD MI455X (est.) |
|---|---|---|---|
| FP4 TFLOPS per chip | 12,600 | Not disclosed | Not disclosed |
| FP8 TFLOPS per chip | Not disclosed | Not disclosed | 20,000 |
| HBM Capacity | 216 GB HBM3e | 192 GB (est.) | 432 GB HBM4 |
| Memory Bandwidth | 6,528 GB/s | Not disclosed | 19,600 GB/s |
| Process Node | TSMC N3 | Not disclosed | TSMC 2nm + 3nm |
| Max Scale (chips) | 1,000,000 | Not disclosed | Not disclosed |
| Price-Performance vs Prior Gen | 2.7x improvement | (baseline) | N/A |
| Performance per Watt vs Prior Gen | 2x improvement | (baseline) | N/A |
The 2.7x training price-performance improvement over Ironwood is Google's stated figure for comparable training jobs. The 2x performance-per-watt improvement is independently significant - as AI training clusters scale to hundreds of megawatts, efficiency gains compound across the power bill. The AMD MI455X has higher raw FP8 throughput and HBM capacity per chip, but Google's scale advantage and Virgo networking enable training regimes that single-node per-chip comparisons don't capture.
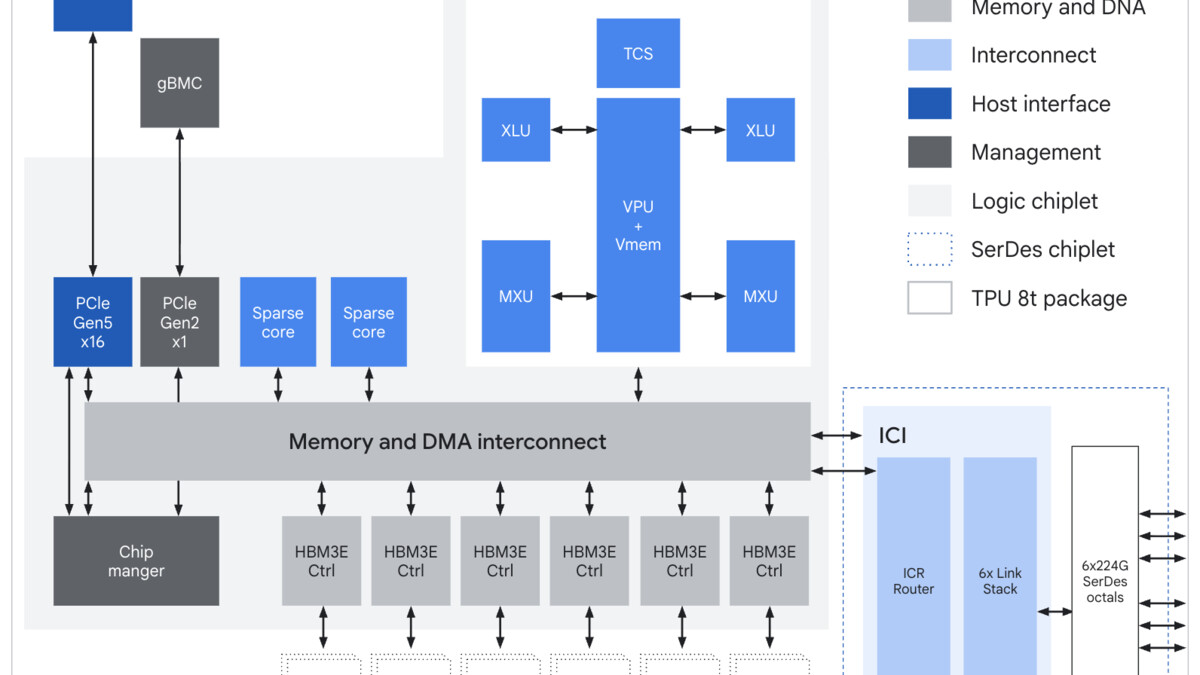 The TPU 8t chip block diagram showing SparseCore, LLM Decoder Engine, HBM3e stacks, and inter-chip interconnect interfaces.
Source: cloud.google.com
The TPU 8t chip block diagram showing SparseCore, LLM Decoder Engine, HBM3e stacks, and inter-chip interconnect interfaces.
Source: cloud.google.com
Key Capabilities
SparseCore and Native FP4. Two hardware units set the 8t apart from the Ironwood. SparseCore is a dedicated accelerator for embedding lookups - the kind of irregular memory access patterns that plague recommendation models and MoE architectures. Standard matrix engines stall on sparse data; SparseCore handles it without blocking the main compute pipeline. Native FP4 support (4-bit floating point) goes further, enabling 2x the theoretical throughput versus FP8 for workloads where FP4 precision is sufficient. Neither of these features appeared in Ironwood.
The Virgo Fabric. Most discussions of TPU 8t focus on per-chip specs, but the Virgo network is arguably the bigger innovation. It delivers up to 47 petabits per second of non-blocking bi-sectional bandwidth across a datacenter, connecting 9,600 TPU 8t chips into a shared-memory training system. Beyond a single datacenter, Google's architecture connects more than 1 million chips across multiple sites into a single logical cluster. This is the infrastructure that makes "train a trillion-parameter model as one job" possible.
Goodput and Reliability. Google reports over 97% goodput (productive compute time) on 8t clusters - meaning less than 3% of scheduled compute is lost to chip failures, link errors, or rerouting. The 8t uses real-time telemetry across tens of thousands of chips, automatic detection and rerouting around faulty interconnect links, and optical circuit switching for hardware reconfiguration without human intervention. In practice, a 9,600-chip superpod running a week-long training job can lose hardware mid-run and continue without manual intervention - a non-trivial engineering accomplishment at that scale.
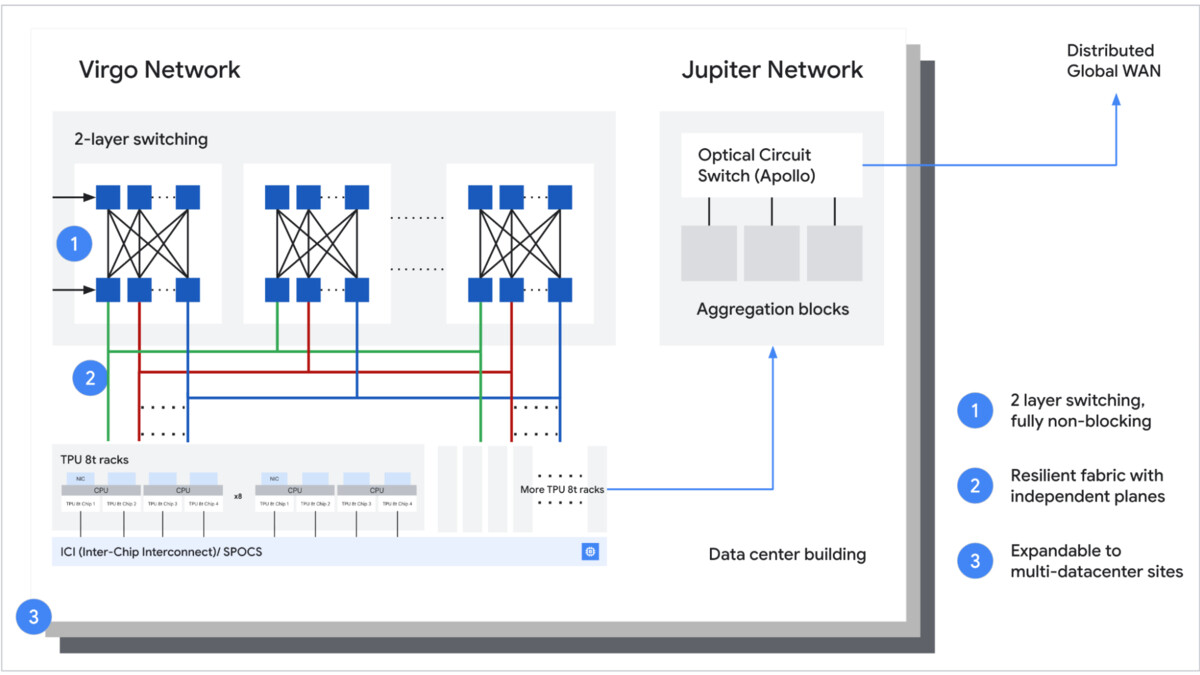 TPU 8t rack-level connectivity to Virgo fabric, showing the datacenter-spanning network architecture.
Source: cloud.google.com
TPU 8t rack-level connectivity to Virgo fabric, showing the datacenter-spanning network architecture.
Source: cloud.google.com
Pricing and Availability
Google has not published pricing. The TPU 8t will be available as a Google Cloud service - there's no option to purchase chips directly. Google usually prices TPU access through per-chip-hour pricing with committed-use discounts, though 8t rates weren't announced with the chip launch.
Availability is scheduled for later in 2026. At the announcement, Google noted that both 8t and 8i would be available "to Cloud customers later this year," without specifying a quarter. Given the announcement at Cloud Next in April, a H2 2026 general availability window is likely.
For competitive context: NVIDIA Vera Rubin and AMD MI455X are also targeting H2 2026 availability. Unlike those chips, the TPU 8t won't be available on-premises or through non-Google cloud providers.
Strengths and Weaknesses
Strengths
- 2.7x better training price-performance over Ironwood (TPU v7)
- 121 FP4 ExaFLOPS per superpod (9,600 chips, 2 PB shared HBM)
- Virgo fabric: up to 47 Pb/s non-blocking bandwidth, scales to 1 million chips
- SparseCore handles embedding lookups without blocking main compute
- Native FP4 support doubles theoretical throughput vs FP8 for compatible workloads
- Over 97% goodput with automatic failure rerouting
- 10x faster storage access via TPUDirect Storage vs Ironwood
Weaknesses
- FP8 performance not disclosed - hard to compare directly with AMD and NVIDIA numbers
- Cloud-only: no on-premises option, no multi-cloud deployment
- Locked to Google Cloud pricing and availability schedules
- 6,528 GB/s per-chip bandwidth is lower than AMD MI455X (19,600 GB/s) and NVIDIA Vera Rubin
- Training-only chip: inference workloads require the separate TPU 8i
- TDP not disclosed; power planning requires engagement with Google Cloud directly
Related Coverage
- Google TPU v7 Ironwood - The predecessor chip, 2.7x less training price-performance
- Google TPU 8i - The companion inference chip announced alongside the 8t
- NVIDIA Vera Rubin NVL144 - The primary competitor for datacenter training scale
- AMD MI455X - AMD's highest-spec training and inference alternative
Sources
✓ Last verified May 1, 2026
