AMD Instinct MI350P - CDNA 4 PCIe Inference Card
AMD Instinct MI350P brings CDNA 4 to a standard PCIe slot: 144GB HBM3E, 4 TB/s bandwidth, 2.3 PFLOPS MXFP8, and 600W passive cooling for air-cooled servers.

TL;DR
- First AMD Instinct PCIe accelerator card in nearly five years - fits standard air-cooled server slots without liquid cooling or custom rack infrastructure
- 144GB HBM3E at 4 TB/s - more memory than a H100 SXM (80GB) and similar bandwidth to the H200 (4.8 TB/s)
- 2.3 PFLOPS MXFP8 / 4.6 PFLOPS MXFP4 - AMD claims roughly 40% faster than the H200 NVL in theoretical FP8/FP16 compute
- No Infinity Fabric between cards - each PCIe MI350P is a standalone unit, limiting multi-card setups to PCIe bandwidth
Overview
The AMD Instinct MI350P is AMD's first PCIe AI accelerator card since the Instinct MI100 era, and the only CDNA 4 product that drops directly into a standard dual-slot PCIe server slot. Every other MI350-series and MI400-series card requires OAM form factor, liquid cooling, or purpose-built rack infrastructure. The MI350P changes that for customers who need high-density AI inference without rebuilding their data center.
The card uses half the MI350X silicon - one I/O die paired with four compute dies - giving it 128 compute units, 512 matrix cores, and 144GB of HBM3E memory across a 4096-bit interface. That memory configuration is meaningful: a single MI350P can hold models that require multiple H100 PCIe cards, making it a genuine upgrade path for on-premises operators who built out H100 PCIe infrastructure. The AMD Instinct MI350X uses the full die with 288GB HBM3E for comparison.
AMD launched the MI350P in May 2026, targeting the large base of existing air-cooled servers in enterprise and mid-market data centers. The pitch is straightforward: you don't need to change your power distribution, cooling plant, or rack layout to get CDNA 4 inference performance. The card runs passively from the server chassis airflow within a 600W board power budget - and an optional 450W mode reduces thermal demand at some performance cost.
Key Specifications
| Specification | Details |
|---|---|
| Manufacturer | AMD |
| Product Family | Instinct MI350 |
| Architecture | CDNA 4 |
| Process Node | TSMC 3nm + 6nm FinFET |
| Chip Type | GPU |
| Compute Units | 128 |
| Stream Processors | 8,192 |
| Matrix Cores | 512 |
| Engine Clock | 2,200 MHz |
| MXFP4 Performance | 4,600 TFLOPS (4.6 PFLOPS) |
| MXFP8 / OCP-FP8 Performance | 2,299 TFLOPS (2.3 PFLOPS) |
| FP16 / BF16 Performance | 1,150 TFLOPS (1.15 PFLOPS) |
| FP64 Performance | 36 TFLOPS |
| Memory | 144GB HBM3E |
| Memory Interface | 4096-bit |
| Memory Bandwidth | 4,000 GB/s (4 TB/s) |
| Form Factor | PCIe Gen5 x16, FHFL dual-slot, 10.5 inches |
| Cooling | Passive (fanless), air-cooled via server chassis |
| TDP | 600W (450W mode available) |
| Power Connector | 12V-2x6 |
| Interconnect | PCIe Gen5 x16 only (no Infinity Fabric) |
| Max Cards per Server | 8 |
| Target Workload | Inference |
| Launch | May 2026 |
| Pricing | Not announced |
Performance Benchmarks
AMD hasn't released third-party benchmark data at launch. The numbers below come from AMD's own publications and the Phoronix review of the MI350P. Independent benchmarking from ServeTheHome and others confirms the memory and architecture specs but not inference throughput now.
| Metric | MI350P | H100 PCIe | H200 SXM5 | MI350X |
|---|---|---|---|---|
| MXFP8 / FP8 (TFLOPS) | 2,299 | 1,513 | 1,979 | ~3,600 (est.) |
| MXFP4 / FP4 (TFLOPS) | 4,600 | N/A | N/A | ~7,200 (est.) |
| FP16 / BF16 (TFLOPS) | 1,150 | 756 | 989 | ~1,800 (est.) |
| Memory Capacity | 144GB | 80GB | 141GB | 288GB |
| Memory Bandwidth | 4,000 GB/s | 2,000 GB/s | 4,800 GB/s | ~6,000 GB/s (est.) |
| TDP | 600W | 350W | 700W | 750W |
| Form Factor | PCIe | PCIe | SXM5 | OAM |
The MI350P beats the H100 PCIe on every compute metric and carries nearly twice the memory. Against the H200 SXM5, the comparison gets more nuanced: MI350P wins on MXFP8 compute (2,299 vs 1,979 TFLOPS) but trails on memory bandwidth (4,000 vs 4,800 GB/s). For inference workloads that are more compute-bound than memory-bandwidth-bound - especially with quantized models at FP4 - the MI350P advantage grows.
The headline comparison AMD cited is a "roughly 40% faster" claim versus the H200 NVL in FP16/FP8 theoretical compute. This appears to compare to the H200 NVL PCIe card (a single-die NVIDIA PCIe product) rather than the NVL72 rack system, though AMD hasn't clarified the specific configuration used in the comparison.
 The MI350P's 10.5-inch passive heatsink design fits a standard dual-slot PCIe slot with no fans of its own.
Source: servethehome.com
The MI350P's 10.5-inch passive heatsink design fits a standard dual-slot PCIe slot with no fans of its own.
Source: servethehome.com
Key Capabilities
Drop-in PCIe Deployment
The MI350P's defining feature is what it doesn't require. OAM-based accelerators like the MI440X and NVIDIA H100 SXM require custom OCP-style server trays, specialized power delivery rails, and often liquid cooling loops. The MI350P plugs into any PCIe Gen5 x16 slot in a standard air-cooled 1U or 2U server, draws from a standard 12V-2x6 connector, and relies entirely on chassis airflow for cooling. That's the same installation process as adding a discrete GPU to a workstation.
For enterprise customers who built out standard server infrastructure for CPU-based workloads and now need AI inference capacity, the MI350P is a meaningful upgrade path that doesn't require a forklift refresh.
ROCm Software Ecosystem
The MI350P runs AMD's ROCm stack, with support from PyTorch, TensorFlow, JAX, and major inference frameworks including vLLM, TGI (Text Generation Inference), and Triton. ROCm support for CDNA 4 launched with the MI350X, so the MI350P inherits the same software maturity rather than waiting for new driver development.
The caveat remains the same as always: CUDA-optimized code doesn't automatically run well on ROCm. Models and inference stacks written for NVIDIA hardware require porting work, and optimized kernels for specific model architectures often lag behind NVIDIA equivalents by months.
Memory Capacity for Large Model Inference
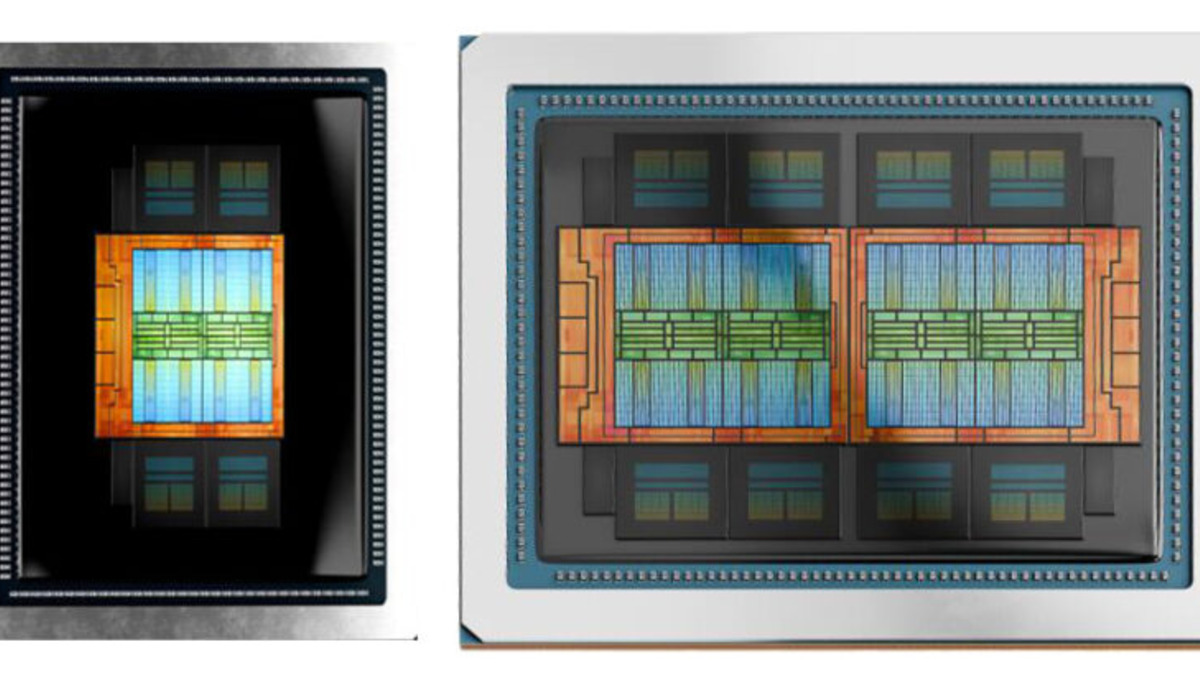 The MI350P (left) uses one I/O die with four compute dies, compared to the full MI350X dual-IOD design.
Source: servethehome.com
The MI350P (left) uses one I/O die with four compute dies, compared to the full MI350X dual-IOD design.
Source: servethehome.com
144GB in a single PCIe card is substantial. A 70-billion-parameter model in BF16 requires roughly 140GB - the MI350P can hold it natively without offloading. At FP8, that same model fits in about 70GB, leaving room for KV cache expansion. For RAG-heavy inference applications with large context windows, that memory headroom matters.
The lack of Infinity Fabric between MI350P cards means multi-card configurations don't share memory transparently - each card is independent from a software perspective. Large-model inference that doesn't fit on 144GB requires tensor-parallel splitting via PCIe Gen5 x16, which can sustain the bandwidth for reasonable model sizes but won't match OAM-based interconnect performance.
Pricing and Availability
AMD launched the MI350P in May 2026. No MSRP has been announced. Street pricing will emerge as server OEM partners - Dell, HP Enterprise, Supermicro, and others - integrate the card into their product lines.
For context: the NVIDIA H100 PCIe 80GB card retailed in the $15,000-$20,000 range at launch, though prices have declined significantly as supply increased. The H200 PCIe commands similar or slightly higher prices. The MI350P targets the same customer base with more memory and better compute-per-dollar potential, though AMD will need to price below NVIDIA's equivalents to overcome the CUDA ecosystem advantage.
Cloud rental pricing for CDNA 4 isn't established yet. AMD's partnership with Meta and Hyperscalers signals interest in large-scale deployment, but public cloud instances running MI350P aren't announced at this time.
Strengths
- Fits standard PCIe slots in air-cooled servers - no infrastructure changes required
- 144GB HBM3E passes any single H100/H200 PCIe card by a wide margin
- 2.3 PFLOPS MXFP8 beats H100 PCIe by ~52% in theoretical compute
- Full CDNA 4 feature set: MXFP4, MXFP8, mixed-precision matrix math
- ROCm support at launch, no wait for driver maturity
Weaknesses
- No Infinity Fabric - multi-card setups limited to PCIe bandwidth for model parallelism
- 600W in a PCIe card requires servers with solid power and airflow; 450W mode reduces performance
- No MSRP announced - pricing uncertainty for procurement planning
- CUDA ecosystem advantage means significant software porting work for most production workloads
- Memory bandwidth (4 TB/s) trails H200 SXM5 (4.8 TB/s) for bandwidth-bound workloads
Related Coverage
- AMD Instinct MI350X - the full OAM-form CDNA 4 flagship with 288GB HBM3E
- AMD Instinct MI440X - AMD's next-gen Instinct with CDNA 5 architecture
- NVIDIA H100 - the benchmark baseline for enterprise AI inference
- NVIDIA H200 - the direct memory-bandwidth competitor
Sources
✓ Last verified June 1, 2026
