
d-Matrix Corsair - In-Memory Inference Accelerator
d-Matrix Corsair is an SRAM-based in-memory compute ASIC in production since June 2026, targeting 10x faster and 5x more power-efficient LLM inference vs GPU baselines.
They summarize our coverage. We write it.
Newsletters like this one rebroadcast our headlines - often without the full review, the source reading, or the analysis underneath. Our weekly briefing sends the work they paraphrase, straight from the desk, before they get to it.
Free, weekly, no spam. One email every Tuesday. Unsubscribe anytime.
d-Matrix Corsair is an SRAM-based in-memory compute ASIC in production since June 2026, targeting 10x faster and 5x more power-efficient LLM inference vs GPU baselines.

OpenAI's first custom AI chip, co-designed with Broadcom on TSMC 3nm, targeting 50% lower inference cost than GPU alternatives.

AMD's CDNA 5 accelerator on TSMC 2nm with 432 GB HBM4 memory - the GPU behind OpenAI's 1GW deployment and Oracle's 50,000-chip supercluster.

AMD Instinct MI350P brings CDNA 4 to a standard PCIe slot: 144GB HBM3E, 4 TB/s bandwidth, 2.3 PFLOPS MXFP8, and 600W passive cooling for air-cooled servers.

NVIDIA RTX Spark is a 20-core ARM + Blackwell GPU superchip delivering 1 petaFLOP FP4 and 128GB unified memory for AI-first Windows laptops and desktops.
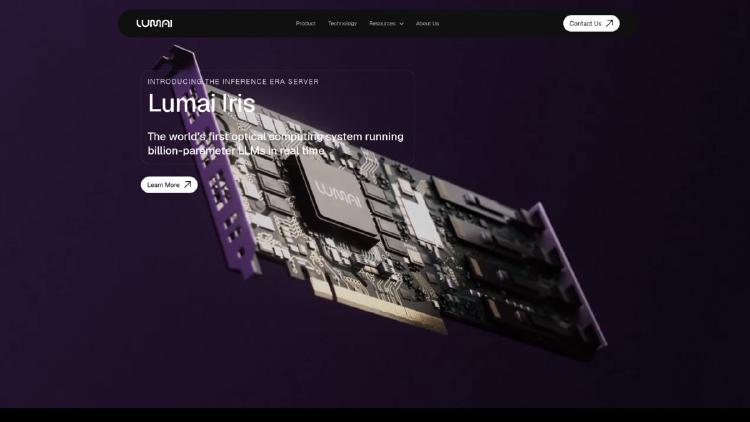
Lumai's optical AI inference server uses light-based computing to run billion-parameter LLMs with up to 90% less power than GPUs.

Skymizer's HTX301 uses six 28nm chips and 384 GB LPDDR5 to run 700B-parameter LLMs on a single PCIe card at just 240W.
Meta's MTIA 450 doubles HBM bandwidth to 18.4 TB/s and adds FlashAttention hardware acceleration for GenAI inference in 2027.

AMD Helios packs 72 Instinct MI455X GPUs and 31 TB HBM4 into a single rack delivering 2.9 FP4 ExaFLOPS for AI workloads.

Meta's second-gen ASIC delivers 6 PFLOPS FP8 and 288 GB HBM for GenAI and recommendation inference inside Meta's data centers.

The Cerebras WSE-3 is the largest chip ever built - a TSMC 5nm wafer with 900,000 AI cores, 44GB SRAM, and 21 PB/s bandwidth. Now powering a $20B OpenAI deal and Amazon Bedrock deployments.

Google's TPU 8i is a purpose-built inference chip with 10.1 FP4 PFLOPs, 288GB HBM3e at 8,601 GB/s, and a Boardfly topology that cuts collective latency 5x for agentic AI workloads.