What Is an LLM? Large Language Models Explained
A large language model is an AI system trained on billions of words to understand and generate human language. Learn how LLMs work, what they can do, and how to pick the right one.

A large language model (LLM) is an AI system trained on massive amounts of text - books, websites, code, conversations - to understand and produce human language. When you type a question into ChatGPT, Claude, or Gemini, an LLM is what reads your words, makes sense of them, and writes back a response that (usually) sounds like it came from a knowledgeable person.
LLMs are behind the chatbots, coding assistants, and AI writing tools that millions of people now use daily. But how do they actually work? What makes one better than another? And what should you watch out for when using them? This guide breaks it all down in plain language.
TL;DR
- A LLM is an AI trained on billions of words to predict and produce text, powered by a neural network architecture called the transformer
- Leading LLMs in 2026 include GPT-5.4, Claude Opus 4.6, Gemini 3, and open-source options like Llama 4 and Mistral Large 3
- LLMs excel at writing, summarizing, coding, and analysis, but still hallucinate facts, carry training biases, and can't verify their own accuracy
- Picking the right model depends on your task, budget, and whether you need speed, accuracy, or privacy
How LLMs Actually Work
Think of an LLM as a very sophisticated autocomplete system. Your phone's keyboard predicts the next word you'll type based on patterns it learned from text. A LLM does the same thing, but at a much larger scale, with far more context, and with enough sophistication to write essays, debug code, and hold nuanced conversations.
Three concepts matter here: tokens, transformers, and training.
Tokens - How LLMs Read Text
LLMs don't read words the way you do. They break text into smaller pieces called tokens - chunks that might be a whole word, part of a word, or even a single character. The word "understanding" might become two tokens: "understand" and "ing." A typical LLM's vocabulary contains 50,000 to 100,000 unique tokens.
Why tokens instead of whole words? Breaking text into subword pieces lets the model handle new words it hasn't seen before. It can recognize "un-" as a prefix and "-ing" as a suffix, so it can work with words it was never explicitly trained on. Every token gets converted into a list of numbers (called a vector) that captures its meaning and relationships to other tokens.
Transformers - The Engine Under the Hood
The transformer is the neural network architecture that makes modern LLMs possible. Introduced in a 2017 research paper by Google called "Attention Is All You Need," it solved a problem that older AI systems struggled with: understanding how words relate to each other across long stretches of text.
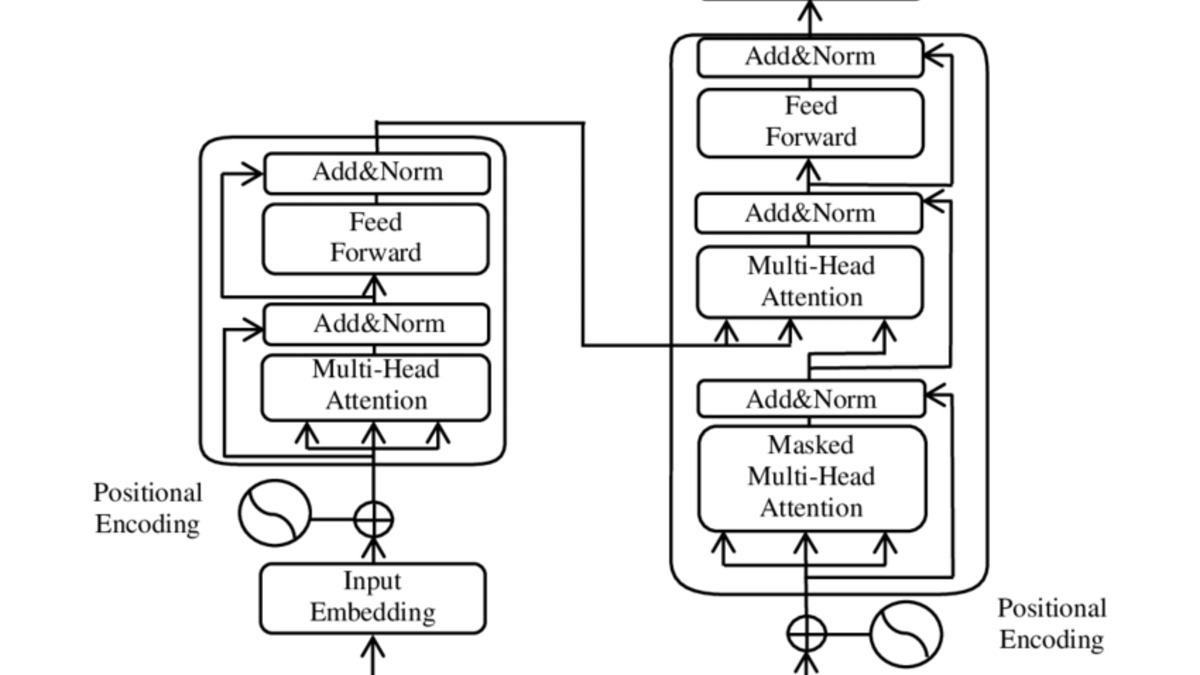 The transformer architecture from the 2017 "Attention Is All You Need" paper. Every major LLM today builds on this design.
Source: arxiv.org
The transformer architecture from the 2017 "Attention Is All You Need" paper. Every major LLM today builds on this design.
Source: arxiv.org
The key innovation is called self-attention. When the model reads a sentence like "The cat sat on the mat because it was tired," self-attention helps it figure out that "it" refers to "the cat" and not "the mat." Older approaches processed words one at a time, left to right. Transformers process entire sequences in parallel, which means they can look at all the words in a passage simultaneously and understand relationships between words that are far apart.
This parallel processing also makes transformers fast to train on modern GPUs, which is why they scaled so quickly from research curiosity to industrial-strength AI systems. It also explains why the transformer - not older architectures like recurrent neural networks - became the foundation for every major LLM.
Training - How LLMs Learn
Training an LLM happens in stages. The first stage, pretraining, exposes the model to enormous datasets - trillions of words from sources like Common Crawl (over 50 billion web pages), Wikipedia, books, scientific papers, and code repositories. During pretraining, the model learns to predict the next token in a sequence. It starts with random guesses and gradually adjusts millions or billions of internal settings (called parameters) until its predictions get reliably good.
GPT-3, released in 2020, had 175 billion parameters. Current frontier models are believed to be significantly larger, though companies like OpenAI and Anthropic no longer publish exact parameter counts.
After pretraining, models go through fine-tuning and reinforcement learning from human feedback (RLHF), where human raters evaluate the model's responses and the system learns to produce answers that are more helpful, accurate, and safe. This is what turns a raw text predictor into something that can follow instructions and carry on a conversation.
 Neural networks like transformers learn by adjusting billions of numerical connections during training.
Source: unsplash.com
Neural networks like transformers learn by adjusting billions of numerical connections during training.
Source: unsplash.com
Major LLMs in 2026
The LLM field has grown fast. Five years ago, GPT-3 was the only game in town. Today, there are dozens of competitive models from multiple companies. Here are the ones that matter most as of March 2026.
| Model | Developer | Context Window | Open/Closed | Best For |
|---|---|---|---|---|
| GPT-5.4 | OpenAI | 1M tokens (API) | Closed | General-purpose, reasoning, computer use |
| Claude Opus 4.6 | Anthropic | 1M tokens | Closed | Long documents, coding, analysis |
| Gemini 3.1 Pro | Google DeepMind | 1M tokens | Closed | Multimodal tasks, Google ecosystem |
| Llama 4 Scout | Meta | 10M tokens | Open-source | On-premises deployment, customization |
| Mistral Large 3 | Mistral AI | 128K tokens | Open (Apache 2.0) | Cost-effective enterprise use |
| DeepSeek V4 | DeepSeek | 128K tokens | Open-weight | Research, budget-conscious teams |
Context windows have exploded. A year ago, 128,000 tokens was considered generous. Now multiple models handle 1 million tokens, and Meta's Llama 4 Scout processes up to 10 million. Bigger context windows mean models can analyze entire books, codebases, or legal filing sets in a single prompt.
For a deeper breakdown of how these models compare on benchmarks, our overall LLM rankings leaderboard tracks scores across coding, reasoning, and multimodal tasks.
What Can LLMs Do?
More than 80% of enterprises will use generative AI APIs or deploy generative AI-enabled applications in production by 2026, according to Gartner. LLMs are the engine behind most of that adoption. The practical applications fall into several broad categories.
Writing and editing. Drafting emails, blog posts, reports, marketing copy, and documentation. LLMs don't replace human writers, but they dramatically speed up first drafts and revisions.
Code generation and debugging. Models like GPT-5.4 and Claude Opus 4.6 can write, explain, and fix code across dozens of programming languages. If you're curious about AI-assisted coding, our vibe coding guide covers how beginners are building apps with AI.
Summarization and analysis. Feed an LLM a 200-page contract, a quarterly earnings report, or a stack of research papers, and it can pull out the key points in seconds. Financial teams that once spent days on quarterly reports now process them in minutes.
Customer service. AI chatbots powered by LLMs handle customer questions around the clock, understanding intent far better than older rule-based systems.
Translation. Modern LLMs handle over 100 languages and produce translations that often rival professional human translators for common language pairs.
Research assistance. LLMs can synthesize information across sources, explain technical concepts, and help researchers survey literature faster. For an overview of how AI handles deeper research tasks, see our deep research guide.
 LLMs power the AI assistants that millions of people use for writing, analysis, and problem-solving every day.
Source: unsplash.com
LLMs power the AI assistants that millions of people use for writing, analysis, and problem-solving every day.
Source: unsplash.com
What LLMs Cannot Do
LLMs are impressive, but they have real limitations that every user should understand before relying on them for anything important.
They Hallucinate
LLMs sometimes create information that sounds confident and plausible but is completely wrong. They might invent fake citations, attribute quotes to people who never said them, or state incorrect statistics as fact. The average hallucination rate across major models fell from roughly 38% in 2021 to about 8.2% in 2026, with the best systems reaching rates as low as 0.7%, according to research from Lakera AI. That's real progress, but 8% is still far too high for anything where accuracy is critical.
The root cause is structural: LLMs predict the most statistically likely next token. They don't have a built-in fact-checking mechanism. They optimize for plausibility, not truth. For a detailed look at how to detect and manage this problem, our hallucinations guide walks through practical strategies.
They Carry Training Biases
LLMs learn from internet text, which contains every bias humans have published online. Reddit threads, personal blogs, academic papers, and news articles all sit side by side in the training data. The model doesn't inherently know which sources are credible or fair. This can result in outputs that reflect gender stereotypes, cultural biases, or political slants.
They Can't Verify Their Own Claims
When you ask an LLM "are you sure about that?" it doesn't actually re-assess its answer against facts. It creates a new response to the question "are you sure?" - which might confidently commit to wrong information. LLMs have no internal mechanism for distinguishing what they know from what they're guessing.
They Have No Real Understanding
LLMs process statistical patterns in language. They don't understand concepts the way humans do. They can't reason from first principles, experience the physical world, or form genuine beliefs. A model that writes beautifully about grief has never felt grief. This matters less for practical tasks and more when people mistake fluent language for actual comprehension.
How to Choose the Right LLM
Choosing a model in 2026 isn't about finding "the best one." It's about matching the right tool to your specific needs. Four factors matter most.
Task type. If you need creative writing or long document analysis, Claude Opus 4.6 excels. For coding, GPT-5.3 Codex and Claude both score well. For multimodal tasks involving images, audio, or video, Gemini 3 leads. Our how to choose an LLM guide goes deeper on matching models to use cases.
Cost. Pricing varies dramatically. Claude Opus 4.6 charges $5 per million input tokens. GPT-5.4 charges similar rates but varies by reasoning effort level. Open-source models like Llama 4 and Mistral are free to download and run on your own hardware, though you pay for the compute.
Speed vs. accuracy. Smaller, faster models (like Gemini Flash or GPT-5.3 Instant) give quick responses for simple tasks. Larger reasoning models take longer but handle complex multi-step problems better. Many teams now use a "model mesh" approach - routing easy queries to fast models and hard queries to powerful ones.
Privacy. If your data can't leave your servers, open-source models you host yourself (Llama 4, Mistral, DeepSeek) are the way to go. Cloud APIs from OpenAI, Anthropic, and Google mean your prompts travel to their servers. For guidance on running models locally, see our guide on running open-source LLMs locally.
FAQ
What does LLM stand for?
LLM stands for Large Language Model. "Large" refers to the billions of parameters (numerical settings) the model uses. "Language Model" means its job is to process and create human language.
Is ChatGPT an LLM?
ChatGPT is a product built on top of an LLM. The LLM underneath is one of OpenAI's GPT models (currently GPT-5.4). ChatGPT adds a user interface, conversation memory, and safety filters on top of the raw model.
Are LLMs free to use?
Some are. Meta's Llama 4 and Mistral's models are free to download and run. ChatGPT, Claude, and Gemini each offer free tiers with usage limits, and paid plans starting around $20 per month for more access.
Can LLMs replace programmers?
Not yet. LLMs can write, explain, and debug code effectively, but they still make mistakes that require human review. They work best as coding assistants that speed up development rather than full replacements.
How much does it cost to train an LLM?
Training a frontier model costs tens to hundreds of millions of dollars in compute alone. GPT-4's training is estimated to have cost over $100 million. Smaller open-source models can be fine-tuned for specific tasks on budgets as low as a few hundred dollars using cloud GPUs.
Do LLMs learn from my conversations?
It depends on the provider. OpenAI uses ChatGPT conversations for training by default (with an opt-out setting). Anthropic and Google have different policies. API usage normally isn't used for training. Always check the provider's data usage policy.
Sources:
- What is LLM? Large Language Models Explained - AWS
- Large Language Models: What You Need to Know in 2026 - HatchWorks AI
- What is a Large Language Model - Cloudflare
- Top 9 Large Language Models as of March 2026 - Shakudo
- It's 2026. Why Are LLMs Still Hallucinating? - Duke University Libraries
- LLM Hallucination Rates 2026 - ModelsLab
- Attention Is All You Need - Vaswani et al. (2017)
- Introducing Claude Opus 4.6 - Anthropic
- Introducing GPT-5.4 - OpenAI
✓ Last verified March 26, 2026

