
AI Safety Leaderboard: Refusal and Jailbreak Rankings
Rankings of AI models by safety metrics including refusal rates, jailbreak resistance, bias scores, and truthfulness across major benchmarks.
They summarize our coverage. We write it.
Newsletters like this one rebroadcast our headlines - often without the full review, the source reading, or the analysis underneath. Our weekly briefing sends the work they paraphrase, straight from the desk, before they get to it.
Free, weekly, no spam. One email every Tuesday. Unsubscribe anytime.
Rankings of AI models by safety metrics including refusal rates, jailbreak resistance, bias scores, and truthfulness across major benchmarks.

Rankings of the best text-to-speech and speech-to-text AI models by naturalness, accuracy, latency, and pricing.

Rankings of the fastest AI models and inference providers by tokens per second, time to first token, and end-to-end latency.

Rankings of the best small language models under 10 billion parameters, comparing Phi-4, Gemma 3, Qwen 3.5, and more across key benchmarks.

Rankings of the best embedding models by MTEB scores, comparing retrieval quality, dimensions, speed, and pricing for RAG and search.

Rankings of the best AI models for multilingual tasks, covering 16 languages across the Artificial Analysis Multilingual Index and MGSM benchmarks.

Rankings of AI models on competition mathematics benchmarks including AIME 2025, IMO, MathArena, and FrontierMath, measuring the cutting edge of mathematical reasoning.

Rankings of the best AI models and agent frameworks on agentic benchmarks measuring real-world task completion, web navigation, function calling, and multi-turn tool use.

Rankings of the best open source LLMs you can run on home hardware - RTX 4090, RTX 3090, Apple M3/M4 Max - organized by VRAM tier with real-world token/s benchmarks and quality scores.
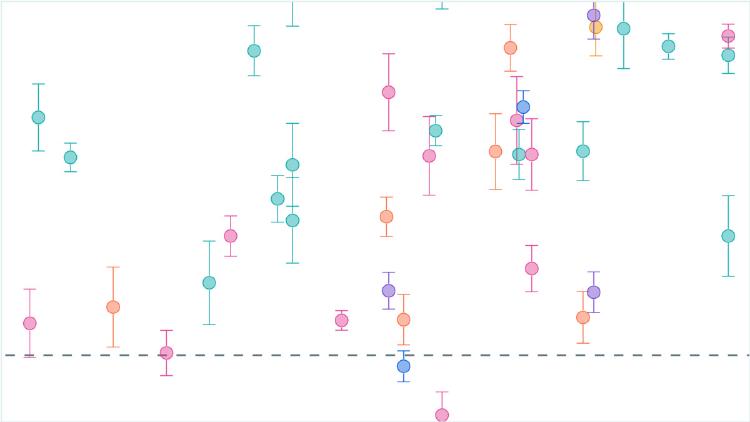
A data-driven look at benchmark contamination, leaderboard gaming, and whether public AI benchmarks can still tell us anything useful about model capabilities.
Rankings of the best AI models for long-context tasks, measuring retrieval accuracy, reasoning, and comprehension across massive context windows from 128K to 10M tokens.

Comprehensive ranking of the top large language models in February 2026, combining multiple benchmarks including reasoning, coding, knowledge, and multimodal capabilities.