Best AI Models for Voice and Speech - March 2026
ElevenLabs Scribe v2 leads speech-to-text at 2.3% WER while ElevenLabs Flash v2.5 sets the pace for TTS with 75ms latency - but Google and Mistral are closing in fast.

TL;DR
- ASR winner: ElevenLabs Scribe v2 at 2.3% WER on AA-WER v2.0 - the most accurate commercial speech-to-text available right now
- TTS winner: ElevenLabs Flash v2.5 at 75ms latency with strong naturalness scores - but quality evaluations are vendor-run, so treat rankings with caution
- Ranking benchmark: Artificial Analysis AA-WER v2.0 for ASR; MOS naturalness ratings and latency for TTS
Voice and speech is now two distinct capability tracks. Speech-to-text (ASR) has a clear quantitative leaderboard built on Word Error Rate. Text-to-speech (TTS) is messier - naturalness is partly subjective, most MOS benchmarks are vendor-run, and latency matters as much as quality for real-time applications. This page covers both, with separate rankings and honest notes about where the data comes from.
Speech-to-Text Rankings
The Artificial Analysis AA-WER v2.0 leaderboard is currently the most credible independent benchmark for commercial ASR APIs. It combines AgentTalk, VoxPopuli, and Earnings22 datasets across 43+ models. Lower WER is better.
| Rank | Model | Provider | AA-WER | Price (per 1,000 min) | Verdict |
|---|---|---|---|---|---|
| 1 | Scribe v2 | ElevenLabs | 2.3% | $6.67 | Highest accuracy, premium price |
| 2 | Gemini 3 Pro | 2.9% | $7.68 | Near-top accuracy at similar cost | |
| 3 | Voxtral Small | Mistral | 3.0% | $4.00 | Best accuracy-to-price ratio right now |
| 4 | Gemini 2.5 Pro | 3.1% | $4.80 | Strong option in mid-price tier | |
| 5 | Gemini 3 Flash | 3.1% | $1.92 | Best budget-accurate trade-off | |
| 6 | Nova-3 | Deepgram | 5.3%* | $2.58 (batch) | Fastest streaming latency in class |
| 7 | Whisper Large v3 | OpenAI | 6.5% | $0.36/hr (via API) | Open-source baseline, 99 languages |
| 8 | Universal-3 Pro | AssemblyAI | 5.9% | $0.45/hr | Best extras: diarization, PII, sentiment |
| 9 | Azure Speech | Microsoft | 7.5% | $1.44/hr (batch) | Broad language and ecosystem coverage |
| 10 | Transcribe | Amazon | 7.6% | $1.44/hr | AWS-native, 100+ languages |
| 11 | Whisper v3 Turbo | OpenAI (via Groq) | 7.75% | $0.04/hr | Fastest cheap option, 6x faster than full |
*Deepgram's own published WER is 5.26% on their internal dataset; AssemblyAI's independent benchmark on 80,000+ files puts Nova-3 at 8.1%. Independent numbers are used here.
Text-to-Speech Rankings
TTS rankings are harder. There's no equivalent of AA-WER for synthesis quality - every major "benchmark" is run by a vendor on their own test set. The numbers below draw on vapi.ai's naturalness comparison and latency data from multiple sources. Treat quality rankings as directional, not definitive.
| Rank | Model | Provider | TTFA Latency | Price (per 1M chars) | Verdict |
|---|---|---|---|---|---|
| 1 | Flash v2.5 | ElevenLabs | 75ms | ~$165-330 (plan-based) | Lowest latency, strong naturalness |
| 2 | Sonic 3 | Cartesia | 40ms | ~$50 | Fastest latency, newer entrant |
| 3 | gpt-4o-mini-tts | OpenAI | 200ms | $0.60 (input) | Cheapest instruction-following TTS |
| 4 | Gemini 2.5 Flash TTS | Not published | $16 (Neural2 pricing) | 30 HD voices, 99 languages | |
| 5 | tts-1-hd | OpenAI | ~200ms | $30 | High quality, straightforward API |
| 6 | Dragon HD Omni | Microsoft Azure | Not published | Varies | 400+ voices, 140 languages |
| 7 | Neural voices | Amazon Polly | Not published | $16 | AWS-native, 29 languages |
| 8 | Flow | Speechmatics | <150ms | $11 | Low latency, EN only for now |
Cartesia Sonic 3 has the lowest raw TTFA at 40ms, but ElevenLabs has a larger voice library and better-documented quality data. OpenAI's gpt-4o-mini-tts is a separate class of model - it accepts natural-language style instructions, which makes it useful for agents that need expressive control rather than raw speed.
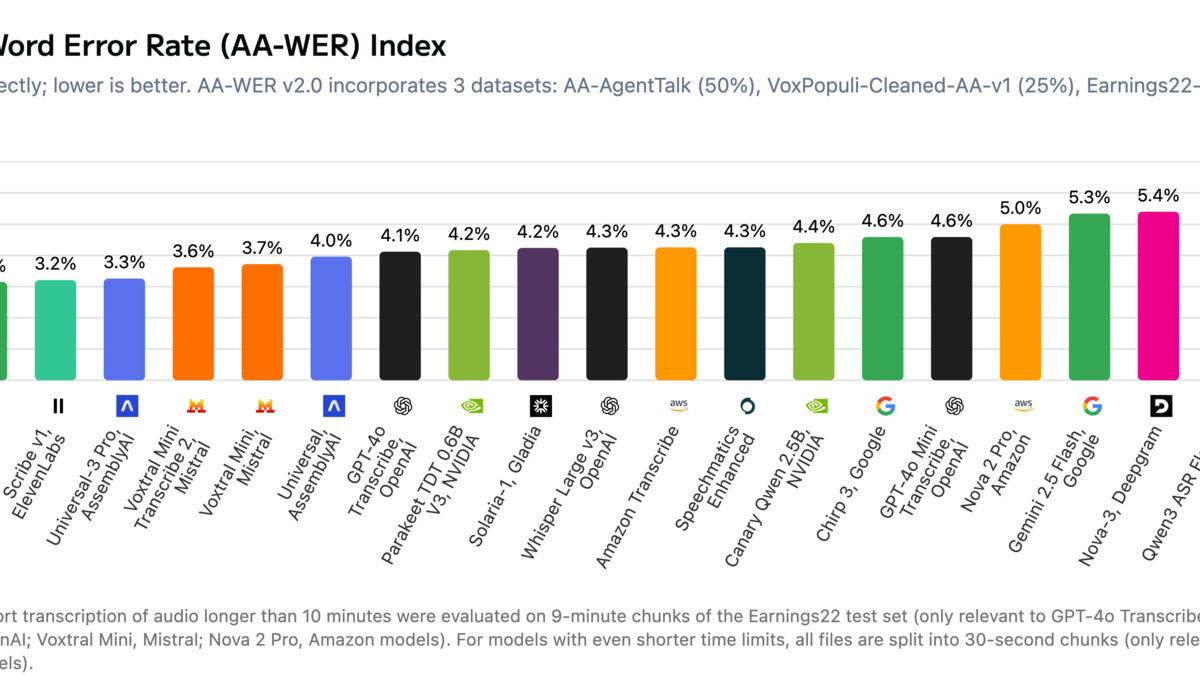 Accuracy vs. price comparison across leading speech-to-text APIs, March 2026.
Source: cdn.sanity.io (Artificial Analysis)
Accuracy vs. price comparison across leading speech-to-text APIs, March 2026.
Source: cdn.sanity.io (Artificial Analysis)
Detailed Analysis
ElevenLabs - Scribe v2 and Flash v2.5
ElevenLabs now spans both sides of the voice stack. Scribe v2 tops the AA-WER leaderboard at 2.3% with sub-150ms latency and 98 language support - roughly a 3x accuracy improvement over their own previous model. Flash v2.5 for TTS delivers 75ms first-audio latency with 70+ languages and 1,200+ voices.
The catch is pricing. At $6.67 per 1,000 minutes for ASR, Scribe v2 costs 3.5x more than Gemini 3 Flash and nearly 20x more than Whisper via OpenAI's API. Their TTS pricing is plan-based rather than per-character, which makes it difficult to compare directly - at the Pro tier ($99/month, 500,000 characters), you're paying roughly $198 per million characters, well above competitors.
Best fit: production voice agents where accuracy and latency both matter, and where per-minute costs are secondary to reliability. For the AI voice generator tools comparison, ElevenLabs consistently places at the top on quality.
Google - Gemini 3 Pro/Flash and Gemini 2.5 TTS
Google's Gemini models have quietly become the strongest combination of accuracy and price in ASR. Gemini 3 Flash hits 3.1% WER at just $1.92 per 1,000 minutes - that's a 60% cost reduction compared to Scribe v2 for only 0.8 percentage points more error. Gemini 2.5 Pro is a strong mid-tier option at $4.80 per 1,000 minutes with 3.1% WER.
On the TTS side, Gemini 2.5 Flash TTS and Gemini 2.5 Pro TTS ship with 30 named HD voices, 99 language auto-detection, and 32k token context. The Gemini Live API enables real-time bidirectional audio for conversational agents. This is the most complete voice stack at a single provider.
The risk is vendor lock-in. Google's voice APIs are tightly coupled to their broader GCP infrastructure, and effective pricing can climb once you account for orchestration and storage.
Mistral - Voxtral Small
Voxtral Small is the unexpected value story right now. At 3.0% WER and $4.00 per 1,000 minutes, it lands in the top three on accuracy while undercutting both ElevenLabs and Google's premium offerings. It also runs at 67.6x real-time speed - fast enough for latency-sensitive applications.
Voxtral is Mistral's first dedicated speech model and has limited track record in production. There's no streaming API yet, and language coverage is narrower than Whisper. For batch transcription workloads where accuracy matters more than features, it's worth testing seriously.
Deepgram - Nova-3 and Self-Reported Data
Nova-3 deserves a note on methodology. Deepgram publishes a 5.26% WER on their own internal dataset and claims a 54% improvement over the nearest competitor. AssemblyAI's independent benchmark on 80,000+ files from varied audio sources puts Nova-3 at 8.1%.
Both figures are plausible - they measure different things. Deepgram's internal test likely uses curated, clean audio; AssemblyAI's benchmark includes phone calls and noisy real-world recordings. Nova-3 does have the best native streaming latency in the commercial tier (under 300ms) and is strong for live transcription in voice agent pipelines.
The AI voice and speech leaderboard on this site tracks these providers more continuously.
Open-Source ASR - Whisper and Beyond
For teams that can run their own infrastructure, the open-source picture is strong. The HuggingFace Open ASR Leaderboard currently ranks NVIDIA's Canary Qwen 2.5B first at 5.63% average WER across 11 datasets, ahead of Whisper Large v3's 7.4%.
Whisper Large v3 remains the default choice for self-hosted ASR - 1.55B parameters, MIT license, 99 language support, around 10GB VRAM. For resource-constrained deployments, Whisper v3 Turbo (809M parameters, ~6GB VRAM) runs 6x faster with less than 0.4 percentage points of accuracy loss. Running it via Groq's API costs $0.04 per hour, making it the cheapest option by a wide margin.
The key Whisper limitation is hallucinations on sparse or low-signal audio. Deepgram's own published study found Whisper's median WER climbed above 53% on real-world phone calls. Any production deployment needs silence detection and confidence filtering on top.
 A microphone studio setup - the hardware side of the voice AI pipeline that Whisper and similar models sit behind.
Source: pexels.com
A microphone studio setup - the hardware side of the voice AI pipeline that Whisper and similar models sit behind.
Source: pexels.com
Methodology
ASR benchmark: Artificial Analysis AA-WER v2.0 combines AgentTalk (conversational AI), VoxPopuli (European Parliament speech), and Earnings22 (financial calls) datasets. This is the most credible independent benchmark available as of March 2026 - it covers real-world audio diversity better than single-dataset tests.
TTS benchmark: No single independent TTS benchmark has the same credibility as AA-WER. Murf AI's blind test (11,000+ audio pairs) and vapi.ai's naturalness ratings are the most cited, but both have methodology limitations. Murf's test was self-conducted; vapi.ai's sample size and diversity aren't fully documented. First-audio latency (TTFA) is more objective and is measured consistently across providers.
Contamination risk: Benchmark scores can be inflated when vendors fine-tune on datasets similar to those used in published evaluations. The WER gap between a provider's own published score and independent benchmarks (see: Nova-3 above) is a signal that this happens.
What's not measured: Speaker diarization accuracy, punctuation quality, domain-specific vocabulary (medical, legal, financial), real-time streaming stability under load, and TTS expressiveness for emotional speech. These matter enormously in production but aren't captured by standard WER or MOS metrics.
Historical Progression
Twelve months ago, Whisper Large v2 was the open-source gold standard and commercial services like Rev AI and Nuance held the accuracy top spots. The landscape shifted quickly.
Q2 2025 - OpenAI releases Whisper Large v3 with a 10-20% error reduction over v2; Whisper Turbo follows, cutting memory requirements by 35% with minimal accuracy loss.
Q3 2025 - Deepgram releases Nova-3, claiming largest accuracy jump in their model history. ElevenLabs enters the ASR market with Scribe, expanding from pure TTS. Gemini 2.5 Flash TTS launches with 30 HD voices and broad language support.
Q4 2025 - NVIDIA Canary Qwen 2.5B tops the HuggingFace Open ASR Leaderboard. Cartesia launches Sonic 3 with 40ms latency, the fastest TTS TTFA measured independently.
Q1 2026 - Mistral releases Voxtral Small and enters the commercial ASR race at 3.0% WER - the first time a model from outside the established voice-AI players reaches the top three. Google's Gemini 3 series posts the first sub-3% WER scores for an affordable commercial API.
The shift over the past year: enterprise speech platforms (Nuance, Google Cloud Speech legacy) have been leapfrogged by developer-focused APIs. Open-source is now competitive enough that the cost-accuracy calculation for self-hosting is truly favorable for high-volume workloads.
 ElevenLabs' voice platform, covering both ASR (Scribe v2) and TTS (Flash v2.5).
Source: nerdynav.com
ElevenLabs' voice platform, covering both ASR (Scribe v2) and TTS (Flash v2.5).
Source: nerdynav.com
FAQ
What's the most accurate speech-to-text API right now?
ElevenLabs Scribe v2 leads at 2.3% WER on the Artificial Analysis AA-WER v2.0 benchmark as of March 2026. Mistral's Voxtral Small is the best value at 3.0% WER for $4.00 per 1,000 minutes.
What's the cheapest ASR API that's still good?
Gemini 3 Flash at $1.92 per 1,000 minutes reaches 3.1% WER - near the top of the leaderboard at a fraction of premium prices. For self-hosted, Whisper v3 Turbo via Groq runs at $0.04 per hour.
Is open-source ASR competitive with commercial APIs?
Yes, for batch workloads. NVIDIA Canary Qwen 2.5B hits 5.63% WER on the HuggingFace Open ASR Leaderboard. The gap to top commercial APIs is about 3 percentage points of WER - significant for high-accuracy needs, acceptable for many production use cases.
Which TTS model has the lowest latency?
Cartesia Sonic 3 measures 40ms TTFA. ElevenLabs Flash v2.5 comes in at 75ms. Both are fast enough for real-time voice agent applications. OpenAI's Realtime API is better for conversational agents that need integrated reasoning and audio in a single loop.
How often do voice AI rankings change?
ASR rankings have shifted substantially every quarter since Q2 2025 as new models enter from unexpected players (Mistral, ElevenLabs). Expect updates to the top five every 2-3 months.
Does Whisper hallucinate?
Yes. Deepgram measured a median WER above 53% on real-world phone call audio for Whisper Large v3. Hallucinations are most common on sparse, noisy, or silent-padded audio. Production deployments need silence detection and confidence thresholds.
Sources:
- Artificial Analysis Speech-to-Text Leaderboard - AA-WER v2.0 scores, pricing, speed data
- Northflank Open Source STT Benchmarks 2026
- AssemblyAI Real-Time STT Comparison
- AssemblyAI Independent Benchmark
- Vapi - ElevenLabs vs OpenAI TTS
- Speechmatics Best TTS APIs 2026
- Deepgram Whisper v3 Real-World Results
- Groq Whisper Large v3 Turbo
- Gemini TTS API Documentation
- HuggingFace Open ASR Leaderboard
- Deepgram Best Speech-to-Text APIs 2026
✓ Last verified March 18, 2026

