Best Models for Long-Context Retrieval - May 2026
Claude Opus 4.6 leads MRCR v2 8-needle at 78% across 1M tokens while Opus 4.7 regressed sharply - GPT-5.5 and DeepSeek V4 Pro are the key new entrants in May 2026.

TL;DR
- Claude Opus 4.6 still leads MRCR v2 8-needle at 78% across 1M tokens - its April 2026 successor, Opus 4.7, fell to 32%
- GPT-5.5 (April 23, 2026) is now #2 at 74%, doubling GPT-5.4's score on the same benchmark
- Four models entered this ranking since March 2026: GPT-5.5, Claude Opus 4.7, DeepSeek V4 Pro, and SubQ
The gap between context window claims and actual retrieval performance has always been the central story here. April 2026 added a new chapter: a model can regress on this capability even as it improves on others. Claude Opus 4.7 launched April 16 and scored 32.2% on MRCR v2 8-needle at 1M tokens - down 46 points from Opus 4.6's 78.3% on the same test. That one number changes every recommendation for anyone choosing a model to process large documents.
GPT-5.5 arrived one week later and took the #2 slot cleanly at 74% on multi-needle retrieval across its full 1M context. DeepSeek V4 Pro followed on April 24 as the first open-weight model to genuinely compete at this level, hitting 59% under the MIT license. A week into May, Subquadratic launched SubQ with a 12M-token research context and 65.9% on the MRCR 1M eval - a credible entrant built on linear-scaling sparse attention rather than standard transformers.
For practical guidance: if precision multi-needle retrieval across million-token documents is what you need, use Opus 4.6. The newer Opus 4.7 isn't a substitute.
Rankings Table
| Rank | Model | Provider | Context | MRCR v2 8-needle | Price (Input) | Verdict |
|---|---|---|---|---|---|---|
| 1 | Claude Opus 4.6 | Anthropic | 200K (1M beta) | 78.3% (1M) | $5/M | Still leads; skip 4.7 for retrieval tasks |
| 2 | GPT-5.5 | OpenAI | 1M | 74.0% (1M) | $5/M | Launched Apr 23; 2x GPT-5.4; standard API |
| 3 | SubQ | Subquadratic | 1M API / 12M research | 65.9% (1M) | ~1/5 frontier cost | Novel architecture; waitlist-only early access |
| 4 | Gemini 3.1 Flash-Lite | 1M | 60.1% | $0.25/M | Best budget multi-needle option | |
| 5 | DeepSeek V4 Pro | DeepSeek | 1M | 59.0% (1M) | $0.44/M | Best open-weight model; MIT license |
| 6 | Claude Opus 4.7 | Anthropic | 1M | 32.2% (1M) | $5/M | 46-point regression from 4.6; strong for coding only |
| 7 | Gemini 3.5 Flash | 1M | 26.6% (1M) | $1.50/M | Launched May 19; solid at 128K, drops at 1M | |
| 8 | Gemini 3.1 Pro | 2M | 26.3% (1M) | $2/M | Largest window; weakest multi-needle at scale | |
| 9 | Gemini 2.5 Pro | 1M | 16.4% | $2.50/M | Strong on coding; poor on 8-needle retrieval | |
| 10 | Llama 4 Scout | Meta | 10M | unrated | Free | Single-needle works; no MRCR 8-needle published |
Two models deserve a footnote outside the main table. Claude Mythos Preview is restricted to approved organizations ($25/$125 per million tokens) and Anthropic reports it leads composite MRCRv2 reasoning - but no independent multi-needle evaluation at 1M has been published, so it can't be ranked here. Gemini 3 Deep Think scores 99% on single-needle NIAH-2 at 1M with a 2M context window, the strongest result on that test, but no MRCR v2 8-needle score has been published for direct comparison.
Detailed Analysis
Claude Opus 4.6 - Still the Benchmark Leader
Nothing in April dethroned Claude Opus 4.6 for multi-needle retrieval. Its 78.3% on MRCR v2 8-needle at 1M tokens remains the highest published result on the hardest standardized retrieval test. At 256K tokens, that rises to 91.9%, which is where most production workloads actually land.
The more interesting story is what it says about its successor. Anthropic built Opus 4.7 around coding and agentic performance - and those benchmarks improved. SWE-bench Verified, terminal tasks, long-horizon coding: all went up. But the attention training changes that drove those gains appear to have traded off retrieval fidelity. This is a known risk when improving for coding and structured generation tasks.
The 1M beta context is still gated to higher-tier API customers. For teams working within 200K, Opus 4.6 has no meaningful competition on multi-needle tasks.
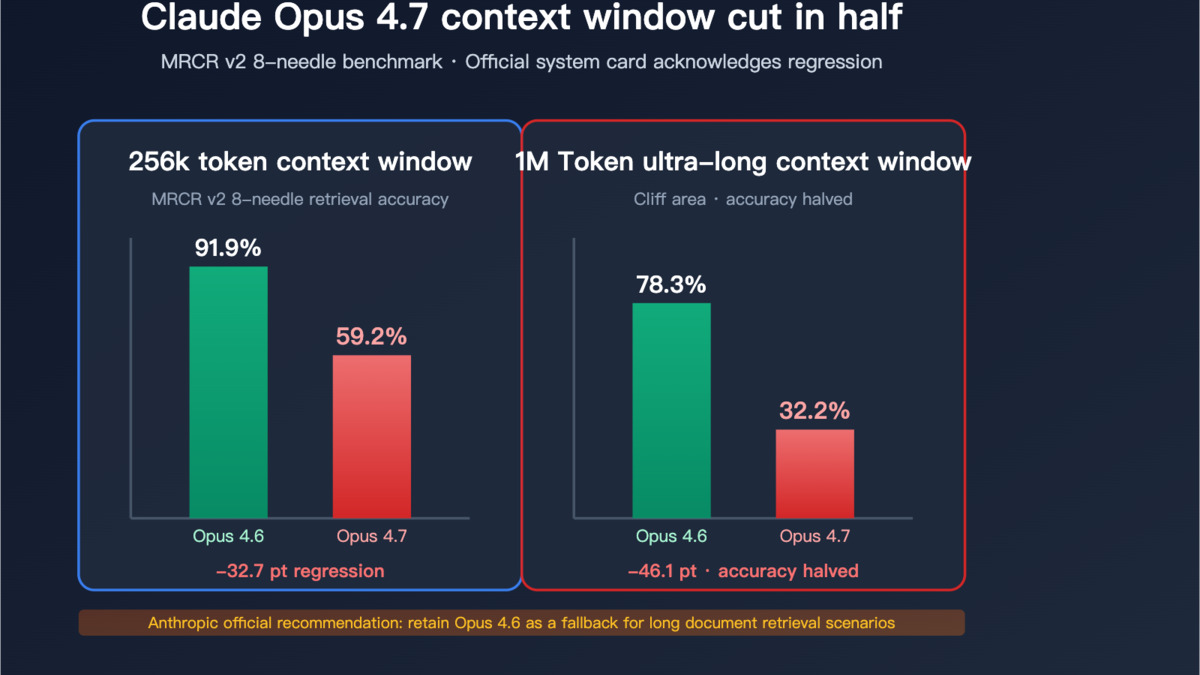 MRCR v2 8-needle scores for Claude Opus 4.6 and 4.7 across context lengths. The regression begins around 128K tokens and becomes severe beyond 256K.
Source: blog.wentuo.ai
MRCR v2 8-needle scores for Claude Opus 4.6 and 4.7 across context lengths. The regression begins around 128K tokens and becomes severe beyond 256K.
Source: blog.wentuo.ai
GPT-5.5 - April's Major New Entrant
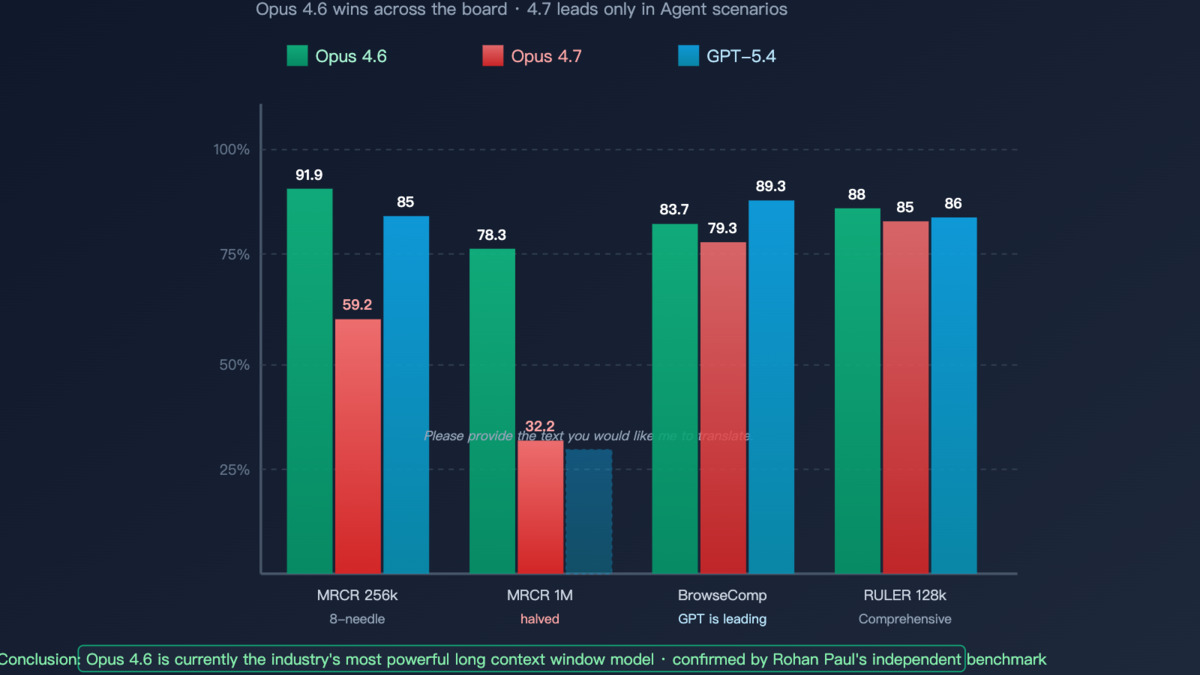
OpenAI released GPT-5.5 on April 23, 2026 with a standard 1M token context window and no beta gating. On MRCR v2 8-needle across the 512K-1M range, it scores 74%, compared to GPT-5.4's 36.6% - a genuine doubling of capability, not a marginal increment.
Beyond retrieval, GPT-5.5 reduced factual error rates by 33% compared to GPT-5.4 on individual claims, and its responses overall are 18% less likely to contain errors. Both matter for long-context work, where a model processes vast amounts of information and needs to synthesize answers accurately from scattered sources.
Pricing is $5/M input and $30/M output - slightly higher output cost than Opus 4.6's $25/M. For teams that need strong retrieval but want a model that's currently under active development (vs. a model that won't be updated further), GPT-5.5 is the cleaner operational choice.
DeepSeek V4 Pro - Best Open-Weight Option
DeepSeek V4 Pro launched April 24 under the MIT license with 59% on MRCR v2 8-needle at 1M tokens. That makes it the strongest open-weight result on this benchmark by a significant margin. Its 1.6 trillion total parameters run with 49B active in MoE mode, and it supports 1M context on both the API and the open weights.
Current API pricing is $0.44/M input and $0.87/M output, representing a 75% promotional discount that runs through May 31. After that, list price returns to $1.74/M input. Even at list price, V4 Pro is a full order of magnitude cheaper than Opus 4.6 for multi-needle workloads.
Single-needle NIAH-2 at 1M shows the model at 78%, which is competitive with frontier proprietary options. The gap between open and closed models on long-context retrieval has narrowed considerably.
SubQ - New Architecture, Early Signals
Subquadratic launched SubQ on May 5, 2026 backed by $29M in seed funding. The model uses Sparse Subquadratic Attention (SSA), which selects a small subset of positions per query token based on content rather than computing full attention. This scales linearly with context length rather than quadratically.
The production API offers 1M tokens; the research model reaches 12M. On MRCR v2 at 1M tokens, SubQ scores 65.9%. On the RULER 128K benchmark, it scores 95% at a claimed cost of $8, compared to ~$2,600 for equivalent Claude Opus processing. The company prices itself at roughly one-fifth of frontier model rates for comparable workloads.
The caveats are real: SubQ is on a private waitlist, doesn't yet have third-party replication of its cost claims, and lacks the breadth of benchmarks that established models have. But the architecture signal is worth tracking. If SSA holds up at scale, the economics of long-context inference change substantially.
 Performance across context lengths for leading models. Scores degrade non-linearly past each model's "reliable zone."
Source: blog.wentuo.ai
Performance across context lengths for leading models. Scores degrade non-linearly past each model's "reliable zone."
Source: blog.wentuo.ai
The Gemini Situation
Google's position in this ranking is puzzling given the company's stated focus on long-context as a differentiator. Gemini 3.1 Flash-Lite posts 60.1% on MRCR v2 8-needle - better than Gemini 3.1 Pro at 26.3%, despite being a smaller Flash-class model. Gemini 3.5 Flash at 26.6% is basically identical to 3.1 Pro.
Gemini 2.5 Pro comes in at 16.4% on the same benchmark. That's a model Google positioned as a coding and reasoning leader with 1M context - but the multi-needle retrieval numbers suggest the 1M window isn't being used reliably for retrieval tasks.
Gemini 3 Deep Think is the standout exception: 99% on single-needle NIAH-2 at 1M with a 2M context window. That result - the best single-needle number from any model at that length - suggests Google's Deep Think architecture handles uniform retrieval highly well. The question is whether that translates to the multi-needle case; no published MRCR 8-needle score exists to verify.
For teams choosing a Google model specifically, Gemini 3.1 Flash-Lite at $0.25/M offers the best retrieval quality at a fraction of 3.1 Pro's cost.
Methodology
Long-context evaluation requires multiple benchmarks because retrieval and reasoning over long contexts are different capabilities:
MRCR v2 8-needle (1M tokens) remains the primary benchmark for this ranking. It asks models to find and reproduce eight specific facts scattered across a million-token prompt. The 8-needle 1M variant is the hardest configuration publicly available. Scores reported here are mean match ratios. Key note: scores from llm-stats.com reflect tested context lengths that may differ from a model's maximum - always verify at your working context length.
NIAH-2 single-needle tests whether a model can find one fact at various depths in a 1M context. Every frontier model now passes simplified versions of this test. It's reported here for models where MRCR data is unavailable, but it differentiates less between the leading models.
AA-LCR (Artificial Analysis Long Context Reasoning) tests multi-step reasoning across documents spanning roughly 100K tokens. This is a different capability from retrieval. GPT-5.3 Codex leads at 75.7%, followed by GPT-5 at 75.6%. Reasoning and retrieval don't necessarily move together - a model strong on one can be weak on the other.
The Opus 4.7 regression case shows why "multi-needle at 1M tokens" matters more than single-needle tests. The model passes simple NIAH tests at 89% - respectable - but collapses to 32% when asked to track eight distinct facts. Production workloads almost always require tracking multiple pieces of information simultaneously, which is why MRCR 8-needle is the metric worth watching.
Historical Progression
March 2025 - Most models topped out at 128K reliable context. GPT-4 Turbo and Claude 3 Opus led at that range. Gemini 1.5 Pro offered 1M tokens but with sharp accuracy drops.
July 2025 - Claude Opus 4.0 and Gemini 2.5 Pro introduced 1M-plus windows. Multi-needle tests emerged as the new frontier metric.
October 2025 - Llama 4 Scout launched with 10M tokens and near-perfect single-needle scores. Its multi-needle and reasoning results were weak, marking the start of the window-size-vs-quality debate.
February 2026 - Claude Opus 4.6 reached 76-78% on MRCR v2 8-needle at 1M tokens, a 4x improvement over its predecessor and the first result that made multi-million-token retrieval production-viable.
April 7, 2026 - Claude Mythos Preview announced with restricted access at $25/$125 per million tokens. Anthropic claims top composite MRCRv2 scores; no independent 8-needle 1M evaluation published.
April 16, 2026 - Claude Opus 4.7 released. Multi-needle retrieval regresses from 78.3% to 32.2% at 1M tokens. Community reaction swift; Anthropic confirms the tradeoff was intentional to improve coding and agentic tasks.
April 23-24, 2026 - GPT-5.5 ships with 74% on MRCR 8-needle, doubling GPT-5.4. DeepSeek V4 Pro follows a day later at 59% under MIT license.
May 5-19, 2026 - SubQ launches with 12M research context and 65.9% MRCR score. Gemini 3.5 Flash arrives May 19 at $1.50/M but scores only 26.6% on multi-needle at 1M, consistent with the broader Gemini pattern.
The window-size race has stalled. No new record was set in April or May on maximum context length. The competition has shifted entirely to retrieval quality and reasoning depth at the lengths that already exist.
FAQ
What's the best model for multi-needle retrieval right now?
Claude Opus 4.6 at 78.3% on MRCR v2 8-needle at 1M tokens. It's the leader despite being months old because its successor regressed. Access to the 1M context is in beta; the 200K default window scores above 90% on the same test.
Why did Claude Opus 4.7 perform worse on long-context retrieval?
Anthropic explicitly optimized Opus 4.7 for coding and agentic performance. The training changes that improved SWE-bench and terminal-task scores appear to have reduced retrieval fidelity. Below 128K tokens, the two models are nearly identical; the regression accelerates sharply beyond 256K.
Is open-source competitive for long-context retrieval?
Yes, as of April 2026. DeepSeek V4 Pro at 59% on MRCR v2 8-needle is within 15 points of the proprietary leader and is MIT-licensed. The gap that existed six months ago has closed substantially.
Does a bigger context window mean better retrieval?
No. Gemini 3.1 Pro has a 2M window but scores 26.3% on 8-needle at 1M. Llama 4 Scout claims 10M tokens but has no published MRCR 8-needle result. Window size and retrieval quality are independent dimensions.
When is a RAG pipeline better than a long-context model?
For most production workloads. RAG offers deterministic source attribution, fresher data, lower latency per query, and predictable costs. Long context works better for tasks requiring holistic understanding of a single large document where you need the full picture in one pass.
How often do rankings change?
Fast - multiple reshuffles happened in the four months before this update. MiniMax M2.5 appeared in the SWE-bench top-5 with no warning. Check lastVerified at the top of this page and the agentic benchmarks leaderboard directly.
Sources:
- LLM Stats - MRCR v2 (8-needle) Benchmark Leaderboard
- WentuoAI - Claude Opus 4.7 Long Context Regression Analysis
- OpenAI - GPT-5.5 Model Reference
- DeepSeek API Docs - V4 Preview Release
- SiliconANGLE - Subquadratic launches with $29M
- Artificial Analysis - Long Context Reasoning Benchmark
- Gemini 3.1 Flash-Lite API Pricing (May 2026)
- GPT-5.5 Benchmarks and Pricing
- Claude Mythos Preview Launch Analysis
- Gemini 3 Deep Think - Long Context Retrieval
- DeepSeek V4 Pro Pricing Guide
- SubQ Review - FelloAI
✓ Last verified May 20, 2026
