Best AI Models for Agentic Tool Use - April 2026
Claude Opus 4.6 leads SWE-bench Verified at 80.8% and OSWorld at 72.7% for agentic tasks, while GPT-5.4 ties for computer use; no single model dominates every workflow type.

TL;DR
- Claude Opus 4.6 leads the combined agentic picture: 80.8% on SWE-bench Verified and 72.7% on OSWorld - the most consistent top-tier scores across both software and computer-use tasks
- Gemini 3.1 Pro ties GPT-5.4 on OSWorld at 75.0% and scores 80.6% on SWE-bench Verified, matching Opus 4.6 at roughly half the price
- SWE-bench Verified is now the sharpest signal for agentic capability - top models cluster between 79-81%, with open-weight options still 20+ points behind
Agentic tool use is the benchmark category where marketing claims diverge most sharply from actual performance. Every major lab now calls their latest model "agentic." The benchmarks tell a more careful story.
As of April 2026, Claude Opus 4.6 holds the strongest combined position: 80.8% on SWE-bench Verified for software engineering tasks and 72.7% on OSWorld for autonomous computer use. Gemini 3.1 Pro is a genuine peer - 80.6% on SWE-bench and 75.0% on OSWorld - at $2/$12 versus Opus 4.6's $5/$25. GPT-5.4 ties Gemini for the OSWorld lead but lacks comparable SWE-bench data.
The headline from this update: no single model controls across all agentic task types. Software engineering agents, computer use agents, and tool-calling agents each have different leaders, and the right choice depends on which workflow you're actually building.
Rankings Table
| Rank | Model | Provider | SWE-bench Verified | OSWorld | BFCL V3 | Price (In/Out) | Verdict |
|---|---|---|---|---|---|---|---|
| 1 | Claude Opus 4.6 | Anthropic | 80.8% | 72.7% | - | $5/$25 | Best combined agentic performance |
| 2 | Gemini 3.1 Pro | 80.6% | 75.0% | - | $2/$12 | Near-Opus quality at half the price | |
| 3 | MiniMax M2.5 | MiniMax | 80.2% | - | - | varies | Surprise top-5 SWE-bench entry |
| 4 | GPT-5.2 | OpenAI | 80.0% | 47.3% | - | $1.75/$14 | Strong SWE-bench, weaker computer use |
| 5 | Claude Sonnet 4.6 | Anthropic | 79.6% | 72.5% | - | $3/$15 | Near-Opus agentic at 40% lower cost |
| 6 | GPT-5.4 | OpenAI | - | 75.0% | - | $2.50/$20 | Computer use pioneer, OSWorld co-leader |
| 7 | Claude Sonnet 4.5 | Anthropic | - | - | - | $3/$15 | TAU-bench retail champion at 86.2% |
| 8 | GLM 4.5 | Zhihu AI | - | - | 76.7% | lower | BFCL function calling leader |
| 9 | GPT-5.3 Codex | OpenAI | - | - | - | $1.75/$14 | Terminal and CLI agentic specialist |
| 10 | DeepSeek V4 | DeepSeek | - | - | - | $0.35/$1.40 | Strongest open-weight option |
| 11 | Kimi K2.5 | Moonshot AI | - | - | - | $1/$5 | Multi-agent coordination |
| 12 | Qwen3 32B | Alibaba | - | - | 75.7% | open | BFCL runner-up, open-weight |
Dashes indicate benchmarks where no verified score is currently available. Our full agentic benchmark leaderboard tracks additional models and updates when new data publishes.
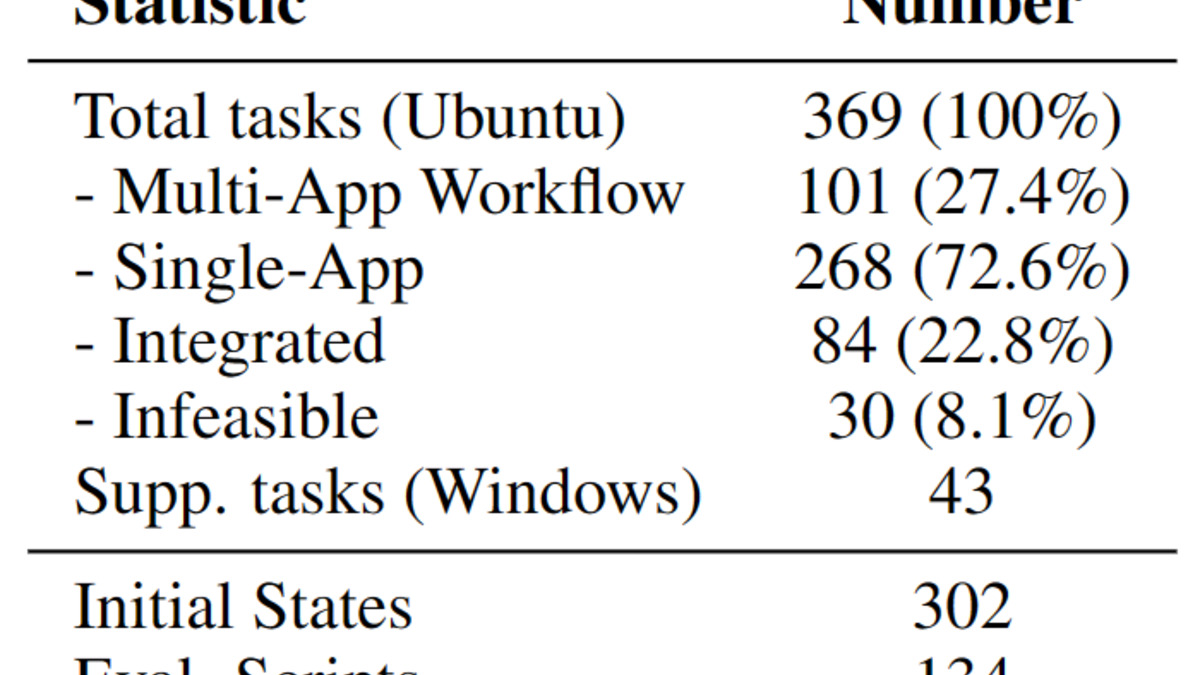 OSWorld's 369 tasks span desktop apps, web browsers, file I/O, and multi-app workflows - far broader than coding-only agentic evaluations.
Source: os-world.github.io
OSWorld's 369 tasks span desktop apps, web browsers, file I/O, and multi-app workflows - far broader than coding-only agentic evaluations.
Source: os-world.github.io
Detailed Analysis
Claude Opus 4.6 - The New Overall Leader
Claude Opus 4.6 moved to the top of the combined agentic rankings this month, driven by its position across two independent high-stakes benchmarks. Its 80.8% on SWE-bench Verified - which tests 500 real software engineering problems from GitHub issues - is essentially tied with Gemini 3.1 Pro (80.6%). On OSWorld, it scores 72.7%, just above the 72.4% human expert baseline.
What separates Opus 4.6 from the competition isn't any single peak score. It's consistency. Most models that lead one agentic benchmark crater on another - GPT-5.2 posts 80.0% on SWE-bench but only 47.3% on OSWorld. Opus 4.6 stays competitive across both.
The tradeoff is cost. At $5/$25 per million tokens, it's the most expensive model in the table. For high-volume agent deployments, Claude Sonnet 4.6 at 79.6% SWE-bench and 72.5% OSWorld offers nearly identical agentic capability at $3/$15.
Read the full Claude Opus 4.6 review for details on long-context agentic workflows and tool call reliability.
Gemini 3.1 Pro - Best Value for Agentic Work
Gemini 3.1 Pro is the strongest argument for not spending $5/$25 on Opus 4.6. At $2/$12, it scores 80.6% on SWE-bench Verified - a 0.2-point difference from Opus 4.6 - and ties GPT-5.4 for the OSWorld lead at 75.0%. The 2M token context window also matters for long-running agentic sessions that build up tool outputs across dozens of steps.
The MCP Atlas benchmark (36 real MCP servers, 220 tools) still shows Gemini 3.1 Pro leading at 69.2%, the data point from our March 2026 update. That score hasn't been surpassed as of publishing. See our MCP server ecosystem leaderboard for the current standings.
The full Gemini 3.1 Pro review covers its function calling reliability in detail.
MiniMax M2.5 - The Surprise Entrant
MiniMax M2.5 appeared in the SWE-bench Verified top-5 with a 80.2% score, placing it ahead of GPT-5.2 when the leaderboard was last captured. This is the biggest shift since our March update. MiniMax has published limited technical detail on how the score was achieved or what agent scaffold was used, which is worth scrutiny - SWE-bench scores can vary notably based on the scaffolding and retry logic around the base model.
Still, the score is third-party verified through the SWE-bench platform. It's the first time a non-Anthropic, non-Google, non-OpenAI model has cracked the SWE-bench top-5 for agentic software engineering.
Pricing and availability outside China remain limited. For production deployment in the US or EU, this is a watch-list item more than a current recommendation.
GPT-5.4 - The Computer Use Specialist
GPT-5.4 remains the computer use leader alongside Gemini 3.1 Pro, both at 75.0% on OSWorld-Verified - above the 72.4% human expert baseline. The computer use leaderboard has full OSWorld and WebArena scores across all models with computer use capabilities.
The gap to note: GPT-5.4 at 75.0% on OSWorld versus 47.3% for GPT-5.2 represents a 27.7-point jump between model generations. Computer use is improving faster than any other agentic sub-category. That arc matters for deployment planning - next-generation models may close gaps that currently favor specialized setups.
The Function Calling Picture
TAU-bench and BFCL V3 add nuance that OSWorld and SWE-bench miss. The Berkeley Function Calling Leaderboard (BFCL V3, as of April 2026) shows GLM 4.5 from Zhipu AI leading at 76.7%, with Qwen3 32B second at 75.7%. Both are lower-cost models that aren't top-tier on SWE-bench or OSWorld. Function calling - in the narrow sense of accurate parameter extraction and API call formatting - is becoming a commodity skill that smaller, cheaper models handle well.
TAU-bench, which tests tool use in realistic customer service dialogues, tells a different story. Claude Sonnet 4.5 leads the retail domain at 86.2%, and the benchmark's telecom domain shows near-saturation (99.3% from LongCat-Flash-Thinking). The practical implication: for structured domain-specific tool calling, you can use cheaper models than the SWE-bench leaderboard suggests.
The Open-Weight Gap
Open-weight models still trail by a wide margin on agentic benchmarks. DeepSeek V4 handles basic tool calling at a fraction of API costs, but independent SWE-bench and OSWorld data for V4 hasn't been published. Qwen3 32B's BFCL score of 75.7% shows competitive function calling in controlled settings, but that doesn't translate to real agentic task completion.
The gap is structurally wider here than in code generation or math reasoning. RLHF-heavy training pipelines - which closed-source labs run at scale - appear to matter more for agentic task completion than for raw capability benchmarks. Open-weight models are within 8-9 points of leaders on HumanEval; on SWE-bench Verified they're 20+ points back.
Methodology
Agentic tool use is the hardest AI capability to benchmark consistently. Rankings here draw from four independent benchmarks:
SWE-bench Verified tests 500 real software engineering problems from GitHub issues, requiring end-to-end repository navigation, patch generation, and test-passing solutions. It's the current gold standard for agentic software engineering because tasks come from production codebases and solutions are mechanically verified.
OSWorld-Verified tests autonomous computer use - GUI navigation, multi-app workflows, file operations - scored against real computer states rather than self-reported outputs. Human expert baseline: 72.4%. See the coding benchmarks leaderboard for additional evaluation context.
TAU-bench evaluates tool-agent-user interaction in realistic customer service scenarios. The retail and telecom domains test whether models can complete goal-directed multi-turn interactions using external tools correctly.
Berkeley Function Calling Leaderboard (BFCL V3) measures narrow function calling: accuracy of parameter extraction, handling of parallel and serial tool calls, and schema compliance across thousands of varied function signatures.
The critical caveat from our March analysis still holds: scaffold choice affects agentic scores by up to 22%, while model choice shifts scores by roughly 1% according to one controlled study. The rankings above reflect model capability under standardized conditions. Your production performance depends heavily on how you wire up the tool loop, retry logic, and context management around whichever model you pick.
Scaffold choice affects agentic scores by up to 22%. Model choice moves scores by roughly 1%. Build the harness first, then optimize the model.
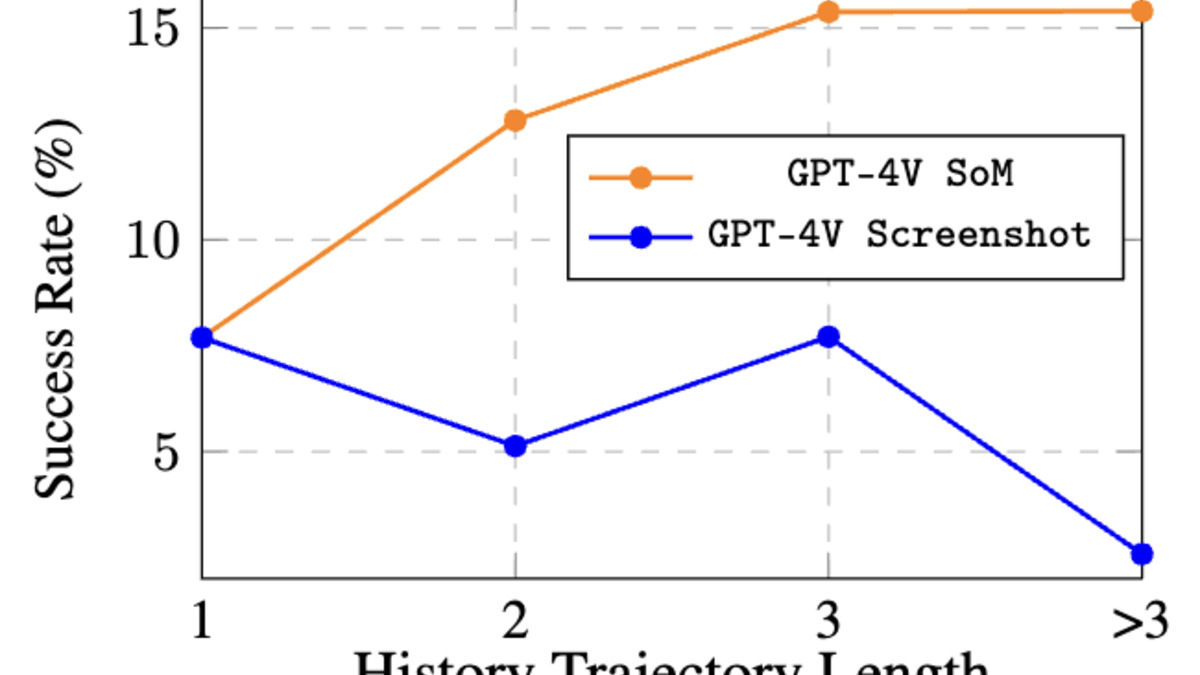 Longer agentic trajectories cause sharper performance drops for some models than others - a key factor when choosing between Opus-tier and Sonnet-tier models for complex workflows.
Source: os-world.github.io
Longer agentic trajectories cause sharper performance drops for some models than others - a key factor when choosing between Opus-tier and Sonnet-tier models for complex workflows.
Source: os-world.github.io
Historical Progression
March 2025 - GPT-4o led function calling benchmarks with roughly 45% on early tool-use evaluations. OSWorld scores hovered around 12-15% for all models.
July 2025 - Claude Opus 4.0 pushed OSWorld past 35%. MCP protocol gained adoption, creating demand for structured tool-use evaluation.
October 2025 - GPT-5.1 reached 47% on OSWorld. Scale AI launched MCP Atlas benchmark. SWE-bench Verified became the dominant software agentic eval.
February 2026 - Gemini 3.1 Pro hit 69.2% on MCP Atlas. Claude Opus 4.6 reached 72.7% on OSWorld.
March 2026 - GPT-5.4 crossed 75% on OSWorld, first model to match human expert baseline. SWE-bench Verified top-5 reached 80%+.
April 2026 - MiniMax M2.5 enters SWE-bench Verified top-5 at 80.2%. GLM 4.5 leads BFCL V3 at 76.7%. Grok 4.20's four-agent architecture enters production testing.
OSWorld went from 15% to 75% in twelve months. SWE-bench Verified scores jumped from the low 40s to 80%+ across multiple models in a similar window. Both trajectories are steeper than any other benchmark category the site tracks.
FAQ
What's the cheapest model for agentic tasks?
DeepSeek V4 at around $0.35/$1.40 handles basic tool calling. For strong performance, Gemini 3.1 Pro at $2/$12 scores 80.6% on SWE-bench Verified and 75.0% on OSWorld.
Is open-source competitive for agentic tool use?
Not at the top level. Open-weight models trail by 20+ points on SWE-bench Verified and OSWorld. Qwen3 32B is competitive on function calling (BFCL), but that doesn't translate to complex multi-step agentic task completion.
How much does the agent scaffold matter?
More than the model choice. One controlled study found scaffold changes shift scores by 22%; model swaps shift scores by roughly 1%. Invest in the harness before optimizing model selection.
Which model is best for computer use specifically?
Gemini 3.1 Pro and GPT-5.4 tie at 75.0% on OSWorld-Verified - both above the human expert baseline of 72.4%. Claude Opus 4.6 follows at 72.7%.
How often do agentic rankings change?
Fast - multiple reshuffles happened in the four months before this update. MiniMax M2.5 appeared in the SWE-bench top-5 with no warning. Check lastVerified at the top of this page and the agentic benchmarks leaderboard directly.
Is Claude Sonnet 4.6 good enough, or do I need Opus 4.6?
For most agentic workflows, yes. Claude Sonnet 4.6 posts 79.6% on SWE-bench Verified and 72.5% on OSWorld - within one point of Opus 4.6 on both benchmarks - at 40% lower cost. The gap widens on long-horizon tasks and professional domain knowledge work.
Sources:
- SWE-bench Verified Leaderboard - swebench.com
- OSWorld Verified Leaderboard - XLANG Lab
- Berkeley Function Calling Leaderboard V3
- TAU-bench Leaderboard
- Scale AI - MCP Atlas Leaderboard
- GPT-4.1 Model Analysis - Artificial Analysis
- Claude 3.7 Sonnet and Claude Code - Anthropic
- LLM Stats - OSWorld Verified
- LLM Stats - SWE-bench Verified
- LLM Stats - TAU-bench Retail
✓ Last verified April 8, 2026
