Best Open-Source LLM Inference Servers 2026
A benchmark-driven comparison of the top open-source LLM inference servers - vLLM, SGLang, TGI, llama.cpp, TensorRT-LLM, LMDeploy, and more.
They summarize our coverage. We write it.
Newsletters like this one rebroadcast our headlines - often without the full review, the source reading, or the analysis underneath. Our weekly briefing sends the work they paraphrase, straight from the desk, before they get to it.
Free, weekly, no spam. One email every Tuesday. Unsubscribe anytime.

AI Benchmarks & Tools Analyst
James is a software engineer turned tech writer who spent six years building backend systems at a fintech startup in Chicago before pivoting to full-time analysis of AI tools and infrastructure. His engineering background means he doesn't just read the spec sheet - he runs the benchmarks, profiles the latency, and checks whether the marketing claims hold up under real workloads.
He studied Computer Science at the University of Illinois at Urbana-Champaign, where he first got hooked on natural language processing during a senior research project on sentiment analysis. He later completed a certificate in data journalism from Northwestern's Medill School.
At Awesome Agents, James owns the leaderboards and tool comparison coverage. He maintains the site's benchmark tracking methodology and is the person who actually runs the numbers before publishing any ranking. He is also an open-source advocate and contributes to several projects in the LLM inference space.
Based in Chicago, IL.
A benchmark-driven comparison of the top open-source LLM inference servers - vLLM, SGLang, TGI, llama.cpp, TensorRT-LLM, LMDeploy, and more.

Rankings of AI models on the key visual reasoning benchmarks - MMMU, MathVista, ChartQA, DocVQA, OCRBench, AI2D, CharXiv, and more - focused on image and document understanding.

A hands-on comparison of the best AI browser agents in 2026 - Perplexity Comet, Dia, Opera Neon, Chrome Gemini, Brave Leo, Fellou, and more - rated on agentic task depth, privacy, price, and platform support.

Rankings of the top embedding and RAG systems across BEIR, MTEB retrieval, MIRACL, MS MARCO, KILT, HotpotQA, and RAGTruth hallucination benchmarks as of April 2026.

A data-driven comparison of the top AI transcription APIs and services for 2026, covering WER accuracy, pricing per hour, speaker diarization, and output formats.

Arcee Trinity-Large-Thinking is a 400B sparse MoE open-source reasoning model that ranks #2 on PinchBench at $0.85/M output tokens, 28x cheaper than Claude Opus 4.6.
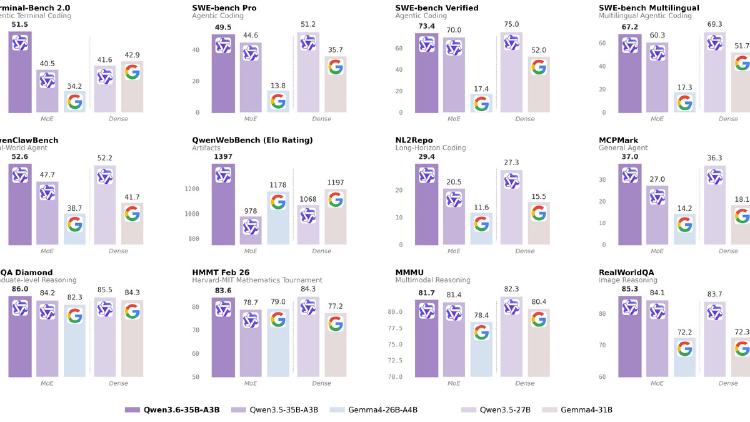
Alibaba's 35B sparse MoE with 3B active parameters delivers 73.4% SWE-bench Verified, multimodal vision and video, 256K context, and DeltaNet hybrid architecture under Apache 2.0.
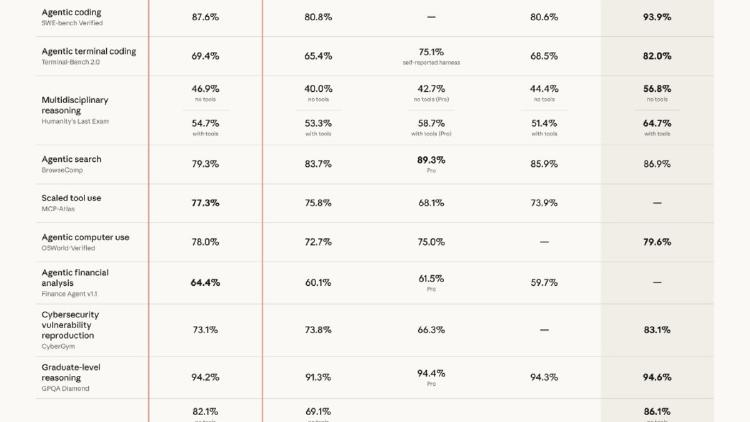
Anthropic's latest flagship model ships with 3x higher resolution vision, a new xhigh effort level, task budgets for cost control, cyber safeguards, and 13% better coding performance at the same $5/$25 pricing.

GPT Image 1.5 leads Artificial Analysis at 1278 Elo while Nano Banana 2 tops Arena.ai - two leaderboards, two answers, and five new models that reshaped the rankings since March.

A hands-on comparison of the top AI unit test generation tools in 2026, covering Qodo Gen, GitHub Copilot, Diffblue Cover, Keploy, and Tusk.

The AMD Instinct MI430X is AMD's CDNA 5 HPC accelerator with 432GB HBM4, full FP64 support, and 19.6 TB/s bandwidth - designed for sovereign AI and scientific supercomputing alongside the MI455X AI GPU.

The NVIDIA Groq 3 LPU is a pure-SRAM inference chip delivering 150 TB/s memory bandwidth and 1.2 PFLOPS FP8 per chip, designed to pair with Vera Rubin GPUs for trillion-parameter model serving.